Программирование и лингвистические данные (syllabus): различия между версиями
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| Строка 135: | Строка 135: | ||
@enduml | @enduml | ||
</uml> | </uml> | ||
=== Пояснения к диаграмме === | |||
Вы уже хорошо знаете digida.mgpu.ru и умеете встраивать туда Voyant Tools, поэтому мы сразу погрузимся в практический workflow курса "Программирование и лингвистические данные". Навыки, которые вы здесь освоите — работа с MediaWiki API, очистка в OpenRefine, анализ в R — универсальны и применимы к любым открытым MediaWiki-площадкам, от ScratchWiki и образовательных вики до вики научных сообществ. Digida мы понимаем лучше всего, но инструменты курса работают на всем образовательном поле интернета! | |||
Начнем с разбора типов лингвистических данных на живых примерах digida: сырые тексты статьи "[[R (язык программирования)]]", токенизированные слова из категории "[[:Категория:Язык программирования]]", морфологические формы в SMW-свойствах, семантические метки вроде "Лингвистика" в Field of knowledge. Вспомните [[VOYANT Tools]] — встроите апплет в тестовую страницу digida и увидите облако слов из категории "Понятие" или тренды частот ScratchWiki-статей о блочных языках. | |||
Процесс, который потом примените где угодно. Сначала выкачаете корпус через [[MediaWiki API]]: составите запрос на 50–100 страниц из категории digida ("Язык программирования") или ScratchWiki ("Educational Programming"), получите JSON/CSV и загрузите в Voyant для первого обзора. Потом откроете данные в [[OpenRefine]]: фасеты, кластеризация, GREL-формулы — уберете дубликаты, нормализуете регистр, получите чистый CSV с колонками "текст", "категория", "дата". | |||
[[R]] - основа курса. Напишете скрипты на tidyverse + tidytext: чтение CSV, токенизация, частоты слов/n-грамм, стоп-слова, группировка по метаданным (dplyr), графики [[ggplot2]] (столбчатые диаграммы, boxplot'ы, тепловые карты), статистика (type-token ratio, сравнение частот). Эти скрипты потом будут на любом MediaWiki-корпусе | |||
Завершением будет мини-проект. Выберете подкорпус (digida о цифровых инструментах, [[ScratchWiki о блочном программировании, вики другого университета), пройдете цикл API → OpenRefine → R/Voyant, сделаете вывод вроде "в статьях о языках программирования чаще производительность, в образовательных — обучение". Оформите как SMW-страницу в категории [[:Категория:CompLing Works]] на digida.mgpu.ru. | |||
Ваша страница будет содержать интерактивный Voyant-апплет, R-код (либо ссылку на GitHub, либо прямо встроенный в <syntaxhighlight lang="R" line>, текст анализа и графики. Это публичный артефакт — другие студенты МГПУ и исследователи увидят вашу работу. | |||
В итоге у вас будет универсальный R-скрипт для любого MediaWiki-корпуса, развернутая SMW-страница в CompLing Works, полный цикл анализа лингвистических данных и портфолио для исследований, публикаций или работы с образовательными вики. | |||
== Лингвистические данные и информатика == | == Лингвистические данные и информатика == | ||
Версия от 06:37, 5 мая 2026
| Планируемые результаты обучения (Знать, Уметь, Владеть) | Цель курса – формирование у студентов магистерской программы "Информатика и английский язык" системных знаний и практических навыков в области современных методов информационного анализа текстовых данных с использованием открытых программных решений.
В результате изучения дисциплины студент должен:
|
|---|---|
| Содержание разделов курса | -
Частотный анализ слов и n-грамм. Статистические метрики в анализе текста: TF-IDF, взаимная информация, коэффициенты ассоциации. Анализ коллокаций и совместной встречаемости слов. Методы визуализации текстовых данных: облака слов, графики частотности, тепловые карты. Сетевой анализ текстов и построение графов слов. Сравнительный анализ текстовых корпусов. Статистические тесты для текстовых данных |
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | R, OpenRefine, VOYANT Tools, MediaWiki, MediaWiki API |
| Книги, на которых основывается учебный курс | APIs for social scientists: A collaborative review, Text Mining with R: A Tidy Approach |
- Для студентов группы Категория:ИНФА-221
Последовательность действий (PlantUML)
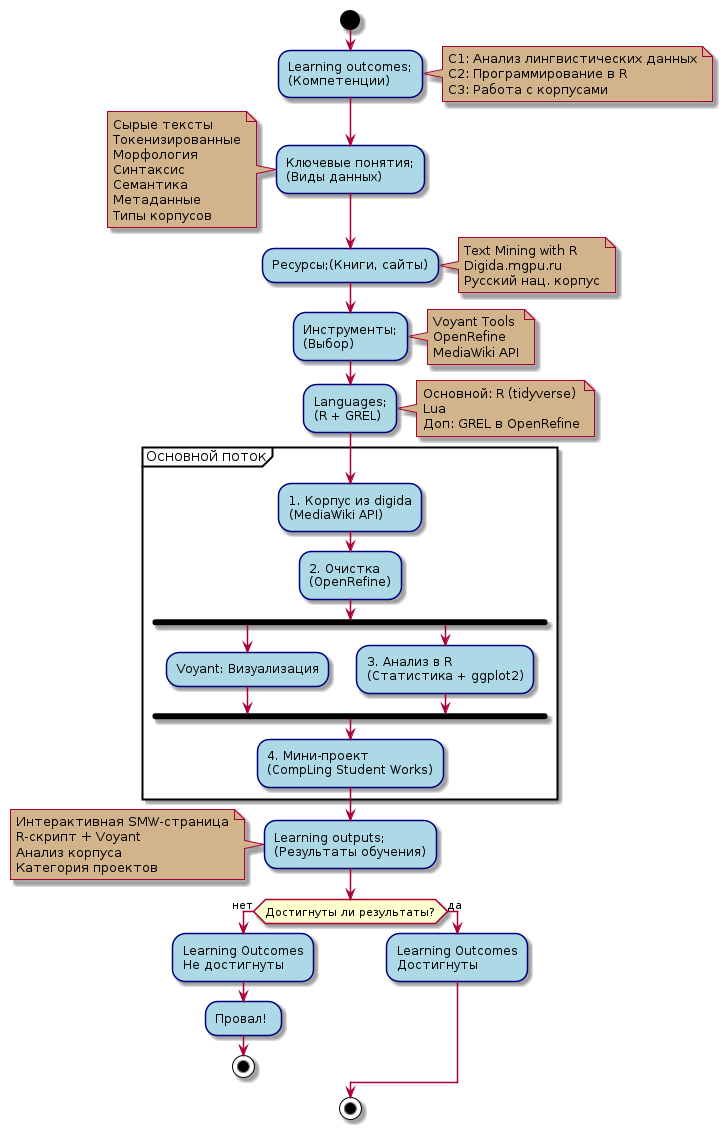
Пояснения к диаграмме
Вы уже хорошо знаете digida.mgpu.ru и умеете встраивать туда Voyant Tools, поэтому мы сразу погрузимся в практический workflow курса "Программирование и лингвистические данные". Навыки, которые вы здесь освоите — работа с MediaWiki API, очистка в OpenRefine, анализ в R — универсальны и применимы к любым открытым MediaWiki-площадкам, от ScratchWiki и образовательных вики до вики научных сообществ. Digida мы понимаем лучше всего, но инструменты курса работают на всем образовательном поле интернета!
Начнем с разбора типов лингвистических данных на живых примерах digida: сырые тексты статьи "R (язык программирования)", токенизированные слова из категории "Категория:Язык программирования", морфологические формы в SMW-свойствах, семантические метки вроде "Лингвистика" в Field of knowledge. Вспомните VOYANT Tools — встроите апплет в тестовую страницу digida и увидите облако слов из категории "Понятие" или тренды частот ScratchWiki-статей о блочных языках.
Процесс, который потом примените где угодно. Сначала выкачаете корпус через MediaWiki API: составите запрос на 50–100 страниц из категории digida ("Язык программирования") или ScratchWiki ("Educational Programming"), получите JSON/CSV и загрузите в Voyant для первого обзора. Потом откроете данные в OpenRefine: фасеты, кластеризация, GREL-формулы — уберете дубликаты, нормализуете регистр, получите чистый CSV с колонками "текст", "категория", "дата".
R - основа курса. Напишете скрипты на tidyverse + tidytext: чтение CSV, токенизация, частоты слов/n-грамм, стоп-слова, группировка по метаданным (dplyr), графики ggplot2 (столбчатые диаграммы, boxplot'ы, тепловые карты), статистика (type-token ratio, сравнение частот). Эти скрипты потом будут на любом MediaWiki-корпусе
Завершением будет мини-проект. Выберете подкорпус (digida о цифровых инструментах, [[ScratchWiki о блочном программировании, вики другого университета), пройдете цикл API → OpenRefine → R/Voyant, сделаете вывод вроде "в статьях о языках программирования чаще производительность, в образовательных — обучение". Оформите как SMW-страницу в категории Категория:CompLing Works на digida.mgpu.ru.
Ваша страница будет содержать интерактивный Voyant-апплет, R-код (либо ссылку на GitHub, либо прямо встроенный в <syntaxhighlight lang="R" line>, текст анализа и графики. Это публичный артефакт — другие студенты МГПУ и исследователи увидят вашу работу.
В итоге у вас будет универсальный R-скрипт для любого MediaWiki-корпуса, развернутая SMW-страница в CompLing Works, полный цикл анализа лингвистических данных и портфолио для исследований, публикаций или работы с образовательными вики.
Лингвистические данные и информатика
Современные подходы к компьютерной обработке естественного языка. Основные направления текстовой аналитики: анализ тональности, тематическое моделирование, анализ стиля.
Программирование на R для анализа лингвистических данных
Основы работы в среде R для анализа текста
- Установка и настройка среды R и RStudio.
- Основы синтаксиса R и принципы tidy data.
- Введение в экосистему tidyverse для анализа данных.
- Специализированные пакеты для работы с текстом: установка и первое знакомство с tidytext, quanteda, tm.
- Основные структуры данных для хранения текста в R.
- Импорт и экспорт текстовых данных различных форматов.
| Description | |
|---|---|
| R | R — язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU. Используется для обработки, анализа и визуализации данных |
| RStudio | свободная среда разработки программного обеспечения с открытым исходным кодом для языка программирования R, который предназначен для статистической обработки данных и работы с графикой. |
Справочные материалы по R
| Description | |
|---|---|
| APIs for social scientists: A collaborative review | В книге представлено множество API социальных сетей и основы их использования. В статье по этой книге собраны примеры API и особенности работы с ними. Код в книге - R |
| Big Data with R | Exploring, Visualizing, and Modeling Big Data with R
|
| Learning analytics methods and tutorials: A practical guide using R | Методы учебной аналитики с использованием языка R - открытое руководство с многочисленными примерами и ссылками на образовательные датасеты |
| R for Data Science | |
| Text Mining with R | Книга даёт завершённую картину современных аналитических подходов к тексту, систематизируя инструменты R и методику работы с данными на всех этапах анализа. |
Лингвистические корпуса и методы их разметки
Предобработка и подготовка текстовых данных
- Этапы предобработки текстовых данных.
- Токенизация: разбиение текста на слова, предложения, n-граммы.
- Нормализация текста: приведение к нижнему регистру, удаление пунктуации и специальных символов.
- Работа со стоп-словами для русского и английского языков.
- Стемминг и лемматизация: принципы и инструменты.
- Создание корпусов и терм-документые матрицы.
- Обработка больших текстовых массивов.
Работа с API
Получение текстовых данных через MediaWiki API
- Введение в MediaWiki API: структура, возможности, ограничения.
- Основные методы получения содержимого страниц.
- Работа с различными форматами данных: wikitext, HTML, plain text.
- Использование пакетов httr и jsonlite для HTTP-запросов в R.
- Создание функций для автоматического извлечения текстов из Wikipedia.
- Обработка метаданных и структурированной информации.
Примеры уроков с использованием MediaWiki API
Данные из Википедии
Урок по анализу данных с использованием методов машинного обучения
Данные из Digida
Статистический анализ и визуализация лингвистических данных
- Частотный анализ слов и n-грамм.
- Статистические метрики в анализе текста: TF-IDF, взаимная информация, коэффициенты ассоциации.
- Анализ коллокаций и совместной встречаемости слов.
- Методы визуализации текстовых данных: облака слов, графики частотности, тепловые карты.
- Сетевой анализ текстов и построение графов слов.
- Сравнительный анализ текстовых корпусов.
- Статистические тесты для текстовых данных
Психолингвистические методы анализа и анализ тональности
- Психолингвистические подходы к анализу текста: выявление личностных характеристик, эмоциональных состояний, психического напряжения.
- Анализ тональности текста и настроений: теоретические основы и практические методы.
- Словарные методы и машинное обучение в анализе тональности.
- Выявление неискренности и психоэмоционального напряжения в тексте.
- Анализ стилистических и грамматических особенностей как индикаторов психологических характеристик.
- Интеграция количественных и качественных методов анализа.
Автоматизация анализа
Интеграция R, Lua, MediaWiki API
Общие критерии оценивания активного эссе
Активное эссе — это интерактивная вики-страница, создаваемая студентом на поле цифровой дидактики с использованием возможностей семантической вики-среды. В отличие от традиционного эссе, активное эссе является «живым» документом, содержащим не только текст, но и программный код, интерактивные модели, структурированные данные, диаграммы и визуализации.
Оценочное средство 1: Активное эссе (страница SMW)
| № | Критерий | Показатели | Баллы | Макс. |
|---|---|---|---|---|
| А. Содержательные критерии | ||||
| 1 | Содержание и соответствие теме дисциплины | Эссе раскрывает заявленную тему, содержит анализ ключевых понятий дисциплины, демонстрирует понимание теоретических основ. Текст логически структурирован: введение, основная часть, выводы. Использована профессиональная терминология. Имеются ссылки на источники. | 0–5 | 5 |
| 2 | Собственная позиция и аргументация | Автор формулирует собственную точку зрения, приводит аргументы и примеры из практики, сравнивает различные подходы, делает обоснованные выводы. | 0–3 | 3 |
| 3 | Научная корректность | Использованы корректные определения и терминология, ссылки на научные источники, отсутствуют фактические ошибки. | 0–2 | 2 |
| Б. Критерии использования возможностей цифровой среды | ||||
| 4 | Использование структурных диаграмм
Построение диаграмм (блок-схемы, UML, графы, диаграммы последовательностей и т.д.) средствами PlantUML, Mermaid или Graphviz |
Диаграммы помогают визуализировать абстрактные концепции: архитектуру систем, алгоритмы, потоки данных, связи между понятиями. Оценивается: корректность нотации, информативность диаграммы, обоснованность выбора типа диаграммы для конкретной задачи. | 0–3 | 3 |
| 5 | Использование семантических возможностей среды
Семантические запросы ( |
Семантические запросы позволяют строить динамические таблицы, выборки и каталоги на основе структурированных свойств страниц. Формы обеспечивают стандартизированный ввод данных. Карты и ленты времени визуализируют пространственные и временны́е отношения. Оценивается: корректность запросов, осмысленность выборки, информативность визуализации. | 0–3 | 3 |
| 6 | Включение математических или химических формул
Использование тегов |
Формулы обеспечивают точную и читаемую запись математических моделей, уравнений и химических реакций. Включение формул демонстрирует владение формальным языком дисциплины и связывает теоретические основы с практикой. Оценивается: корректность записи, осмысленность использования, связь с текстом. | 0–2 | 2 |
| 7 | Включение программного кода
Использование тегов |
Программный код в эссе демонстрирует практические навыки: способность автоматизировать обработку данных, реализовать алгоритмы, воспроизвести результаты анализа. Подсветка синтаксиса и нумерация строк повышают читаемость. Оценивается: работоспособность кода, наличие комментариев, связь с темой, оригинальность решения. | 0–3 | 3 |
| 8 | Включение интерактивных приложений
Встраивание проектов Snap!, Scratch или иных визуальных программных сред |
Интерактивные приложения позволяют читателю эссе непосредственно взаимодействовать с программными моделями: запускать симуляции, менять параметры, наблюдать результаты. Это превращает эссе из статического текста в интерактивную учебную среду. Оценивается: работоспособность приложения, связь с темой, уровень интерактивности. | 0–3 | 3 |
| 9 | Работа с внешними данными
Подключение внешних источников данных, их фильтрация и представление в виде таблиц (расширение External Data) |
Подключение внешних данных позволяет работать с реальными, актуальными наборами данных (открытые данные, API, базы данных), а не с искусственными примерами. Фильтрация и представление в таблицах демонстрируют навыки работы с данными. Оценивается: релевантность источника, корректность фильтрации, информативность представления. | 0–3 | 3 |
| 10 | Включение многоагентных моделей NetLogo
Встраивание моделей NetLogo для демонстрации агентных симуляций |
Многоагентные модели позволяют исследовать сложные системы: показать, как простые правила поведения агентов порождают макроуровневые паттерны. Встраивание модели в эссе даёт читателю возможность запустить симуляцию, изменить параметры и самостоятельно исследовать результаты. Оценивается: соответствие модели теме, корректность настройки параметров, наличие пояснений. | 0–3 | 3 |
| Итого максимум | 30 | |||
Шкала перевода баллов:
| Баллы | Оценка |
|---|---|
| 25–30 | Отлично (A) |
| 19–24 | Хорошо (B) |
| 13–18 | Удовлетворительно (C) |
| 0–12 | Неудовлетворительно (F) |
Оценочное средство 2: История вклада участника
| № | Критерий | Показатели | Баллы | Макс. |
|---|---|---|---|---|
| 1 | Равномерность вклада по времени | Работа над эссе велась регулярно на протяжении всего периода обучения, а не концентрировалась в последний момент. История правок показывает итеративное развитие текста: от замысла к черновику, от черновика к финальной версии. Отсутствуют признаки массового копирования (крупные единовременные вставки неоригинального текста). | 0–3 | 3 |
| 2 | Качество итерационного развития | Каждая правка содержит содержательные изменения (дополнение аргументации, улучшение кода, добавление визуализаций), а не формальные косметические правки. Прослеживается логика развития работы. | 0–2 | 2 |
| 3 | Участие в обсуждении | Участник вносил вклад в обсуждение на страницах обсуждения эссе однокурсников: задавал вопросы, предлагал улучшения, давал конструктивную обратную связь. | 0–2 | 2 |
| Итого максимум | 7 | |||
Оценочное средство 3: Зачёт (демонстрация активного эссе)
| № | Критерий | Показатели | Баллы | Макс. |
|---|---|---|---|---|
| 1 | Знание программного материала | Знание программного материала и структуры дисциплины, умение показать свои знания при демонстрации активного эссе. Свободная ориентация в содержании эссе, способность ответить на вопросы по материалу. | 0–2 | 2 |
| 2 | Владение методологией дисциплины в цифровой среде | Демонстрация уверенного владения инструментами цифровой среды, использованными в эссе: объяснение выбора конкретных средств (диаграммы, код, модели, запросы), умение модифицировать элементы эссе в реальном времени. | 0–2 | 2 |
| 3 | Презентация и ответы на вопросы | Логичность изложения, ясность речи, способность аргументировать свои решения, готовность к дискуссии. | 0–1 | 1 |
| Итого максимум | 5 | |||
Зачёт выставляется при суммарном балле не менее 3 из 5.
Итоговая оценка по дисциплине
| Компонент | Максимум | Вес |
|---|---|---|
| Активное эссе | 30 | 60% |
| История вклада | 7 | 20% |
| Зачёт | 5 | 20% |
| Итого | 42 | 100% |
Самостоятельные индивидуальные или парные работы студентов
В категории - Категория:CompLing Works
- API Sandbox Климова
- LuaLearning модули Михайлова Софья
- R-script Егоров
- R-script Карпов
- R-script Климова
- R-script Стулин
- R-script Хадижа
- R-script анализ датасета Жильцов Даниил
- R-script анализ датасета Хадижа
- R-скрипт Петрова Ульяна Павловна
- R-скрипт анализ Шишкова Дарья
- R-скрипт анализ датасета Ключникова Дарья
- R-скрипт анализа Конухова Анастасия
- Voyant Tools Егоров Виталий
- Voyant Tools Жильцов Даниил
- Voyant Tools Карпов Семён
- Voyant Tools Климова
- Voyant Tools Ключникова Дарья
- Voyant Tools Конухова Анастасия
- Voyant Tools Михайлова София
- Voyant Tools Петрова Ульяна Павловна
- Voyant Tools Стулин
- Voyant Tools Хадижа
- Voyant Tools Шишкова Дарья
- Анализ датасета с помощью R-скрипта Михайлова Софья
- Запрос в Песочницу API Егоров Виталий
- Запрос в Песочницу API Жильцов Даниил
- Запрос в Песочницу API Ключникова Дарья
- Запрос в Песочницу API Михайлова Софья
- Запрос в Песочницу API Стулин
- Запрос в Песочницу API Хадижа
- Запрос в песочницу API Шишкова Дарья
- Запрос в песочницу Карпов
- Описательная статистика R Карпов
- Описательная статистика R Климова
- Описательная статистика R Петрова Ульяна Павловна
- Описательная статистика R Стулин
- Очистка и разметка OpenRefine Хадижа
- Очистка и разметка в OpenRefine Ключникова Дарья
- Песочница API Конухова Анастасия
- Статистическое сравнение Жильцов Даниил
- Статистическое сравнение Стулин
- Статистическое сравнение Хадижа
- Статистическое сравнение страниц
- Статистическое сравнение страниц Егоров Виталий
- Статистическое сравнение страниц Петрова Ульяна Павловна
- Статистическое сравнение страниц про роботов
- Статистическое сравнение текстов Шишкова Дарья

