Программирование и лингвистические данные (syllabus): различия между версиями
Patarakin (обсуждение | вклад) Нет описания правки |
Patarakin (обсуждение | вклад) |
||
| Строка 48: | Строка 48: | ||
}} | }} | ||
* Для студентов группы [[:Категория:ИНФА-221]] | * Для студентов группы [[:Категория:ИНФА-221]] | ||
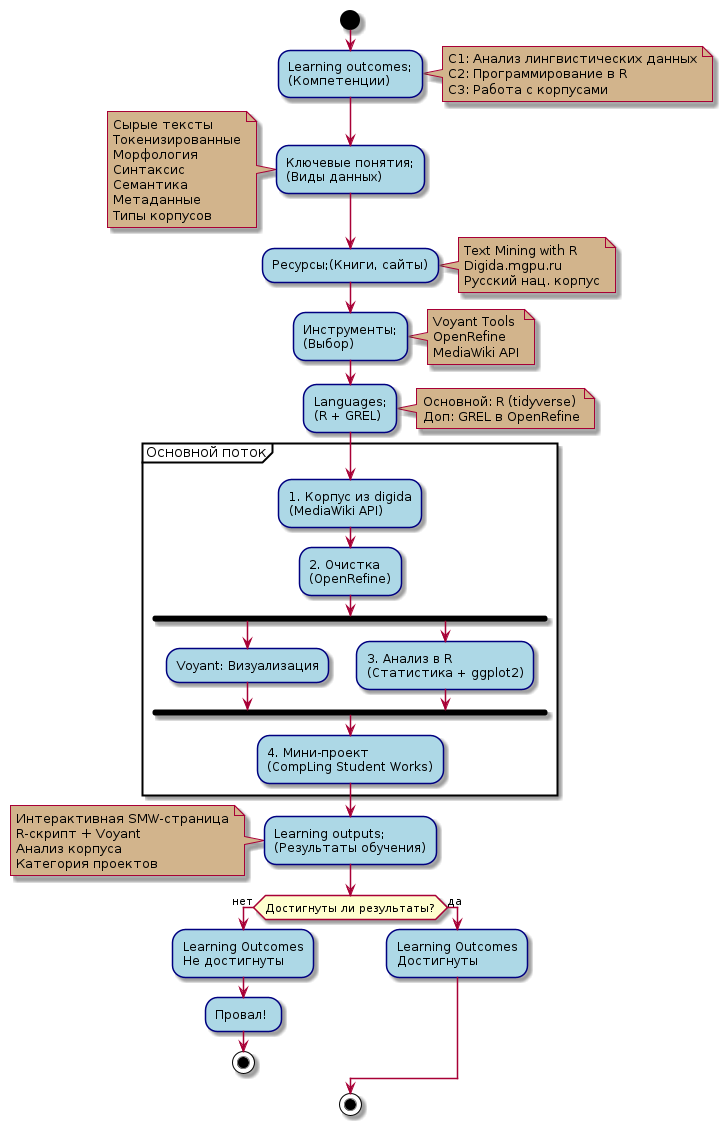
== Последовательность действий ([[PlantUML]]) == | |||
<uml> | |||
@startuml | |||
skinparam NoteBackgroundColor tan | |||
skinparam backgroundColor white | |||
skinparam activity { | |||
BackgroundColor lightblue | |||
BorderColor navy | |||
} | |||
start | |||
:Learning outcomes;\n(Компетенции); | |||
note right | |||
C1: Анализ лингвистических данных | |||
C2: Программирование в R | |||
C3: Работа с корпусами | |||
end note | |||
:Ключевые понятия;\n(Виды данных); | |||
note left | |||
Сырые тексты | |||
Токенизированные | |||
Морфология | |||
Синтаксис | |||
Семантика | |||
Метаданные | |||
Типы корпусов | |||
end note | |||
:Ресурсы;(Книги, сайты); | |||
note right | |||
Text Mining with R | |||
Digida.mgpu.ru | |||
Русский нац. корпус | |||
end note | |||
:Инструменты;\n(Выбор); | |||
note right | |||
Voyant Tools | |||
OpenRefine | |||
MediaWiki API | |||
end note | |||
:Languages;\n(R + GREL); | |||
note right | |||
Основной: R (tidyverse) | |||
Доп: GREL в OpenRefine | |||
end note | |||
partition "Основной поток" { | |||
:1. Корпус из digida\n(MediaWiki API); | |||
:2. Очистка\n(OpenRefine); | |||
fork | |||
:Voyant: Визуализация; | |||
fork again | |||
:3. Анализ в R\n(Статистика + ggplot2); | |||
end fork | |||
:4. Мини-проект\n(CompLing Student Works); | |||
} | |||
:Learning outputs;\n(Результаты обучения); | |||
note left | |||
Интерактивная SMW-страница | |||
R-скрипт + Voyant | |||
Анализ корпуса | |||
Категория проектов | |||
end note | |||
if (Достигнуты ли результаты?) then (нет) | |||
:Learning Outcomes\nНе достигнуты; | |||
:Провал! ; | |||
stop | |||
else (да) | |||
:Learning Outcomes\nДостигнуты; | |||
endif | |||
stop | |||
@enduml | |||
</uml> | |||
== Лингвистические данные и информатика == | == Лингвистические данные и информатика == | ||
Версия от 08:53, 10 февраля 2026
| Планируемые результаты обучения (Знать, Уметь, Владеть) | Цель курса – формирование у студентов магистерской программы "Информатика и английский язык" системных знаний и практических навыков в области современных методов информационного анализа текстовых данных с использованием открытых программных решений.
В результате изучения дисциплины студент должен:
|
|---|---|
| Содержание разделов курса | -
Частотный анализ слов и n-грамм. Статистические метрики в анализе текста: TF-IDF, взаимная информация, коэффициенты ассоциации. Анализ коллокаций и совместной встречаемости слов. Методы визуализации текстовых данных: облака слов, графики частотности, тепловые карты. Сетевой анализ текстов и построение графов слов. Сравнительный анализ текстовых корпусов. Статистические тесты для текстовых данных |
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | R, OpenRefine, VOYANT Tools, MediaWiki, MediaWiki API |
| Книги, на которых основывается учебный курс | APIs for social scientists: A collaborative review, Text Mining with R: A Tidy Approach |
- Для студентов группы Категория:ИНФА-221
Последовательность действий (PlantUML)
Лингвистические данные и информатика
Современные подходы к компьютерной обработке естественного языка. Основные направления текстовой аналитики: анализ тональности, тематическое моделирование, анализ стиля.
Программирование на R для анализа лингвистических данных
Основы работы в среде R для анализа текста
- Установка и настройка среды R и RStudio.
- Основы синтаксиса R и принципы tidy data.
- Введение в экосистему tidyverse для анализа данных.
- Специализированные пакеты для работы с текстом: установка и первое знакомство с tidytext, quanteda, tm.
- Основные структуры данных для хранения текста в R.
- Импорт и экспорт текстовых данных различных форматов.
| Description | |
|---|---|
| R | R — язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU. Используется для обработки, анализа и визуализации данных |
| RStudio | свободная среда разработки программного обеспечения с открытым исходным кодом для языка программирования R, который предназначен для статистической обработки данных и работы с графикой. |
Справочные материалы по R
| Description | |
|---|---|
| APIs for social scientists: A collaborative review | В книге представлено множество API социальных сетей и основы их использования. В статье по этой книге собраны примеры API и особенности работы с ними. Код в книге - R |
| Big Data with R | Exploring, Visualizing, and Modeling Big Data with R
|
| Learning analytics methods and tutorials: A practical guide using R | Методы учебной аналитики с использованием языка R - открытое руководство с многочисленными примерами и ссылками на образовательные датасеты |
| R for Data Science | |
| Text Mining with R | Книга даёт завершённую картину современных аналитических подходов к тексту, систематизируя инструменты R и методику работы с данными на всех этапах анализа. |
Лингвистические корпуса и методы их разметки
Предобработка и подготовка текстовых данных
- Этапы предобработки текстовых данных.
- Токенизация: разбиение текста на слова, предложения, n-граммы.
- Нормализация текста: приведение к нижнему регистру, удаление пунктуации и специальных символов.
- Работа со стоп-словами для русского и английского языков.
- Стемминг и лемматизация: принципы и инструменты.
- Создание корпусов и терм-документые матрицы.
- Обработка больших текстовых массивов.
Работа с API
Получение текстовых данных через MediaWiki API
- Введение в MediaWiki API: структура, возможности, ограничения.
- Основные методы получения содержимого страниц.
- Работа с различными форматами данных: wikitext, HTML, plain text.
- Использование пакетов httr и jsonlite для HTTP-запросов в R.
- Создание функций для автоматического извлечения текстов из Wikipedia.
- Обработка метаданных и структурированной информации.
Примеры уроков с использованием MediaWiki API
Данные из Википедии
Урок по анализу данных с использованием методов машинного обучения
Данные из Digida
Статистический анализ и визуализация лингвистических данных
- Частотный анализ слов и n-грамм.
- Статистические метрики в анализе текста: TF-IDF, взаимная информация, коэффициенты ассоциации.
- Анализ коллокаций и совместной встречаемости слов.
- Методы визуализации текстовых данных: облака слов, графики частотности, тепловые карты.
- Сетевой анализ текстов и построение графов слов.
- Сравнительный анализ текстовых корпусов.
- Статистические тесты для текстовых данных
Психолингвистические методы анализа и анализ тональности
- Психолингвистические подходы к анализу текста: выявление личностных характеристик, эмоциональных состояний, психического напряжения.
- Анализ тональности текста и настроений: теоретические основы и практические методы.
- Словарные методы и машинное обучение в анализе тональности.
- Выявление неискренности и психоэмоционального напряжения в тексте.
- Анализ стилистических и грамматических особенностей как индикаторов психологических характеристик.
- Интеграция количественных и качественных методов анализа.
Автоматизация анализа
Интеграция R, Lua, MediaWiki API
Самостоятельные индивидуальные или парные работы студентов
В категории - Категория:CompLing Works
- API Sandbox Климова
- LuaLearning модули Михайлова Софья
- R-script Егоров
- R-script Карпов
- R-script Климова
- R-script Стулин
- R-script Хадижа
- R-script анализ датасета Жильцов Даниил
- R-script анализ датасета Хадижа
- R-скрипт Петрова Ульяна Павловна
- R-скрипт анализ Шишкова Дарья
- R-скрипт анализ датасета Ключникова Дарья
- R-скрипт анализа Конухова Анастасия
- Voyant Tools Егоров Виталий
- Voyant Tools Жильцов Даниил
- Voyant Tools Карпов Семён
- Voyant Tools Климова
- Voyant Tools Ключникова Дарья
- Voyant Tools Конухова Анастасия
- Voyant Tools Михайлова София
- Voyant Tools Петрова Ульяна Павловна
- Voyant Tools Стулин
- Voyant Tools Хадижа
- Voyant Tools Шишкова Дарья
- Анализ датасета с помощью R-скрипта Михайлова Софья
- Запрос в Песочницу API Егоров Виталий
- Запрос в Песочницу API Жильцов Даниил
- Запрос в Песочницу API Ключникова Дарья
- Запрос в Песочницу API Михайлова Софья
- Запрос в Песочницу API Стулин
- Запрос в Песочницу API Хадижа
- Запрос в песочницу API Шишкова Дарья
- Запрос в песочницу Карпов
- Описательная статистика R Карпов
- Описательная статистика R Климова
- Описательная статистика R Петрова Ульяна Павловна
- Описательная статистика R Стулин
- Очистка и разметка OpenRefine Хадижа
- Очистка и разметка в OpenRefine Ключникова Дарья
- Песочница API Конухова Анастасия
- Статистическое сравнение Жильцов Даниил
- Статистическое сравнение Стулин
- Статистическое сравнение Хадижа
- Статистическое сравнение страниц
- Статистическое сравнение страниц Егоров Виталий
- Статистическое сравнение страниц Петрова Ульяна Павловна
- Статистическое сравнение страниц про роботов
- Статистическое сравнение текстов Шишкова Дарья

