Анализ и интерпретация данных (syllabus): различия между версиями
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| (не показаны 33 промежуточные версии 2 участников) | |||
| Строка 1: | Строка 1: | ||
{{Curriculum | |||
|Learning_outcomes=В результате освоения дисциплины слушатель должен: | |||
; Знать | |||
* особенности типов и источников данных | |||
; Уметь: | |||
* планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML диаграмм (plantUML, MerMaid) | |||
* использовать сетевые сервисы для экспресс-анализа и интерпретации данных (RAWGraphs) | |||
* очищать, обрабатывать и видоизменять данные, приводя их к опрятному виду tidy data (Snap!, R) | |||
* совершать операции статистического анализа | |||
; Владеть: | |||
* навыками выстраивания процесс анализа и интерпретации данных от исходных сырых данных до публикации отчета или статьи | |||
* навыками выращивания данных в искусственных сообществах (NetLogo, GAMA) | |||
|Description=Разделы: | |||
# Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества | |||
# Планирование операций над данными | |||
# Блочные сервисы визуализации данных | |||
# Блочные языки обработки и представления данных | |||
|Environment=BehaviorSpace, NetLogo, Scratch, Snap!, Сообщество Scratch, CODAP, RStudio, RAWGraphs | |||
}} | |||
== Составляющие курса == | |||
=== Составляющие поля совместной деятельности === | |||
<graphviz> | <graphviz> | ||
digraph Digida1 { | digraph Digida1 { | ||
| Строка 18: | Строка 39: | ||
участники ; | участники ; | ||
события ; | события ; | ||
диаграммы | диаграммы ; | ||
среда | |||
node[color="#FF0000",fontsize=14, fontcolor="white",style=filled, shape="box"] ; | node[color="#FF0000",fontsize=14, fontcolor="white",style=filled, shape="box"] ; | ||
| Строка 24: | Строка 46: | ||
} | } | ||
</graphviz> | </graphviz> | ||
=== UML диаграмма - последовательность учебного курса === | |||
<uml> | |||
@startuml | |||
skinparam NoteBackgroundColor tan | |||
start | |||
:Competence ; | |||
note right | |||
Explore or solve problems by selecting technology for data analysis | |||
; | Select effective technology to represent data | ||
Sorting files, emails or database returns to clarify clusters of related information | |||
end note | |||
:Concept; | |||
note left | |||
Аналитика учебная | |||
Мультимодальная аналитика | |||
Цифровой след | |||
Командная наука | |||
API | |||
CSV | |||
Dashboard | |||
Flowchart | |||
JSON | |||
Prompt | |||
Team Assembly | |||
end note | |||
:Книги; | |||
note right | |||
A new kind of science | |||
Agent-Based and Individual-Based Modeling: A Practical Introduction | |||
Turtles, termites, and traffic jams | |||
R for Data Science | |||
Tidy Modeling with R | |||
end note | |||
:Authors; | |||
note left | |||
Latour | |||
Турчин | |||
Ершов | |||
Barabashi | |||
end note | |||
:Данные; | |||
note right | |||
Books (dataset) | |||
GoogleSchool 01(dataset) | |||
Letopisi 2006 (dataset) | |||
end note | |||
:Цифровые средства; | |||
fork | |||
:plantUML ; | |||
fork again | |||
:Mermaid; | |||
fork again | |||
:RAWGraphs; | |||
fork again | |||
:CODAP; | |||
fork again | |||
:Semantic MediaWiki; | |||
fork again | |||
:VOSviewer; | |||
end fork | |||
:Модели ; | |||
note left | |||
Segregation (model) | |||
Traffic jams | |||
Urban Suite - Awareness | |||
GenderDeSegregationSchool | |||
Multi-mediator model | |||
Piaget-Vygotsky (model) | |||
School Choice ABM | |||
School Education Competition | |||
end note | |||
:Среды моделирования ; | |||
note right | |||
end note | |||
fork | |||
:Snap! ; | |||
fork again | |||
:StarLogo Nova; | |||
fork again | |||
:NetLogo; | |||
fork again | |||
:R; | |||
end fork | |||
fork | |||
:Scripting Tutorials ; | |||
note left | |||
end note | |||
fork again | |||
:Project; | |||
note right | |||
end note | |||
end fork | |||
stop | |||
@enduml | |||
</uml> | |||
==== | == С какими данными и что мы будем делать == | ||
Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества | |||
{{#ask: [[Аналитика учебная]] OR [[Аналитика мультимодальная]] | ?Description }} | |||
Например, мы отправляемся в [[Lens]] и собираем там данные о [[Аналитика мультимодальная|мультимодальной аналитике]] | |||
[[ | === Собственные данные вики и их визуализация === | ||
; [[Dashboard]] | |||
====== | {| class="wikitable" | ||
! Страниц | |||
! Статей | |||
! Редактирований | |||
! Участников | |||
! Файлов | |||
{{!}}- | |||
{{!}} {{NUMBEROFPAGES:R}} | |||
{{!}} {{NUMBEROFARTICLES:R}} | |||
{{!}} {{NUMBEROFEDITS:R}} | |||
{{!}} {{NUMBEROFUSERS:R}} | |||
{{!}} {{NUMBEROFFILES}} | |||
|} | |||
---- | |||
{{#ask: [[Категория:DigitalTool]] [[Tool_is_made_for::+]] | |||
|?Tool_is_made_for | |||
|mainlabel=- | |||
|format=jqplotchart | |||
|charttype=bar | |||
|height= 600 | |||
|filling=1 | |||
|distribution= yes | |||
|min = 1 | |||
|width=100% | |||
|direction=horizontal | |||
|theme=simple | |||
|colorscheme=rdbu | |||
}} | |||
==== Библиографические данные ==== | |||
[https://app.vosviewer.com/?json=https://drive.google.com/uc?id=1vYgqSwG2d1X3RyNDt1AA_mDRIDo0B2ZG Пример работы] | |||
[[ | [[Zotero]] + ACM https://m.youtube.com/watch?v=vNvRVTWYwlw | ||
[[Библиографический датасет 1]] | |||
== Внешние данные == | |||
# https://corgis-edu.github.io/corgis/ | |||
## https://corgis-edu.github.io/corgis/csv/graduates/ | |||
#### https://corgis-edu.github.io/corgis/datasets/csv/graduates/graduates.csv | |||
См. [[:Категория:Dataset]] | |||
== Выращивание данных == | |||
[[Как вырастить данные в искусственном сообществе]] | |||
==== Многое как данные на примере Snap! ==== | ==== Многое как данные на примере Snap! ==== | ||
| Строка 111: | Строка 228: | ||
[[:Категория:Diagrams]] | [[:Категория:Diagrams]] | ||
=== Сетевые сервисы визуализации === | === Сетевые сервисы визуализации === | ||
| Строка 182: | Строка 243: | ||
* в пакетах [[R]] и [[Python]] – использование tidyverse & tidygraph | * в пакетах [[R]] и [[Python]] – использование tidyverse & tidygraph | ||
Мы берём исходный датасет - [[Cities (dataset)]] | Мы берём исходный [[датасет]] - [[Cities (dataset)]] | ||
{{#get_web_data:url=http://www.uic.unn.ru/pustyn/data-sets/digida/Millions_Cities.csv | {{#get_web_data:url=http://www.uic.unn.ru/pustyn/data-sets/digida/Millions_Cities.csv | ||
| Строка 200: | Строка 261: | ||
|} | |} | ||
Внутри множество городов - миллионников из разных стран. И у всех координаты в виде | |||
Пример очистки и преобразования данных: | Пример очистки и преобразования данных: | ||
| Строка 208: | Строка 270: | ||
=== Статистический анализ и интерпретация данных === | === Статистический анализ и интерпретация данных === | ||
Основные операции статистического анализа | Основные операции статистического анализа - [[Анализ данных]] | ||
=== Экспорт результатов === | === Экспорт результатов === | ||
| Строка 214: | Строка 276: | ||
== Литература == | == Литература == | ||
=== | |||
=== Тексты на поле вычислительной дидактики === | |||
=== Дополнительная литература === | === Дополнительная литература === | ||
# Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359. | # Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359. | ||
# Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112. | # Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112. | ||
== Критерии оценки по дисциплине == | == Критерии оценки по дисциплине == | ||
| Строка 235: | Строка 296: | ||
| Примеры источников данных | | Примеры источников данных | ||
| Найти, оформить, вырастить данные для дальнейшего анализа | | Найти, оформить, вырастить данные для дальнейшего анализа | ||
| В категории статей о датасетах [[:Category: | | В категории статей о датасетах [[:Category:Dataset]] | ||
|- | |- | ||
| планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | | планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | ||
| Строка 249: | Строка 310: | ||
| Сетевые сервисы визуализации | | Сетевые сервисы визуализации | ||
| Использовать экспресс-методы | | Использовать экспресс-методы | ||
| | | [[RAWGraphs]], [[CODAP]], [[graphviz]] - примеры использования | ||
|- | |- | ||
| Обработать и очистить данные | | Обработать и очистить данные | ||
| Строка 259: | Строка 320: | ||
| Статистический анализ и интерпретация данных | | Статистический анализ и интерпретация данных | ||
| Операции над собственным датасетом | | Операции над собственным датасетом | ||
| Готовые датасеты | | Готовые датасеты [[:Category:Dataset]] | ||
|- | |- | ||
| Подготовка выполняемой публикации | | Подготовка выполняемой публикации | ||
| Строка 267: | Строка 328: | ||
|} | |} | ||
=== Словарик курса === | |||
{{#ask: [[CSV]] OR [[Dashboard]] OR [[Flowchart]] OR [[JSON]] OR [[Агент]] OR [[Акторно-сетевая теория]] OR [[Аналитика учебная]] OR [[Библиографическая запись]] OR [[Выращивание данных]] OR [[Данные образовательные]] OR [[Гистограмма]] | ?Description }} | |||
---- | |||
[[Категория:РУП]] | [[Категория:РУП]] | ||
Текущая версия от 16:18, 28 мая 2025
| Планируемые результаты обучения (Знать, Уметь, Владеть) | В результате освоения дисциплины слушатель должен:
|
|---|---|
| Содержание разделов курса | Разделы:
|
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | BehaviorSpace, NetLogo, Scratch, Snap!, Сообщество Scratch, CODAP, RStudio, RAWGraphs |
| Книги, на которых основывается учебный курс |
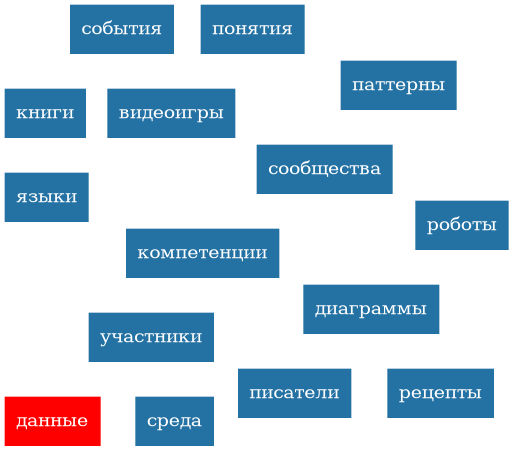
Составляющие курса
Составляющие поля совместной деятельности
UML диаграмма - последовательность учебного курса
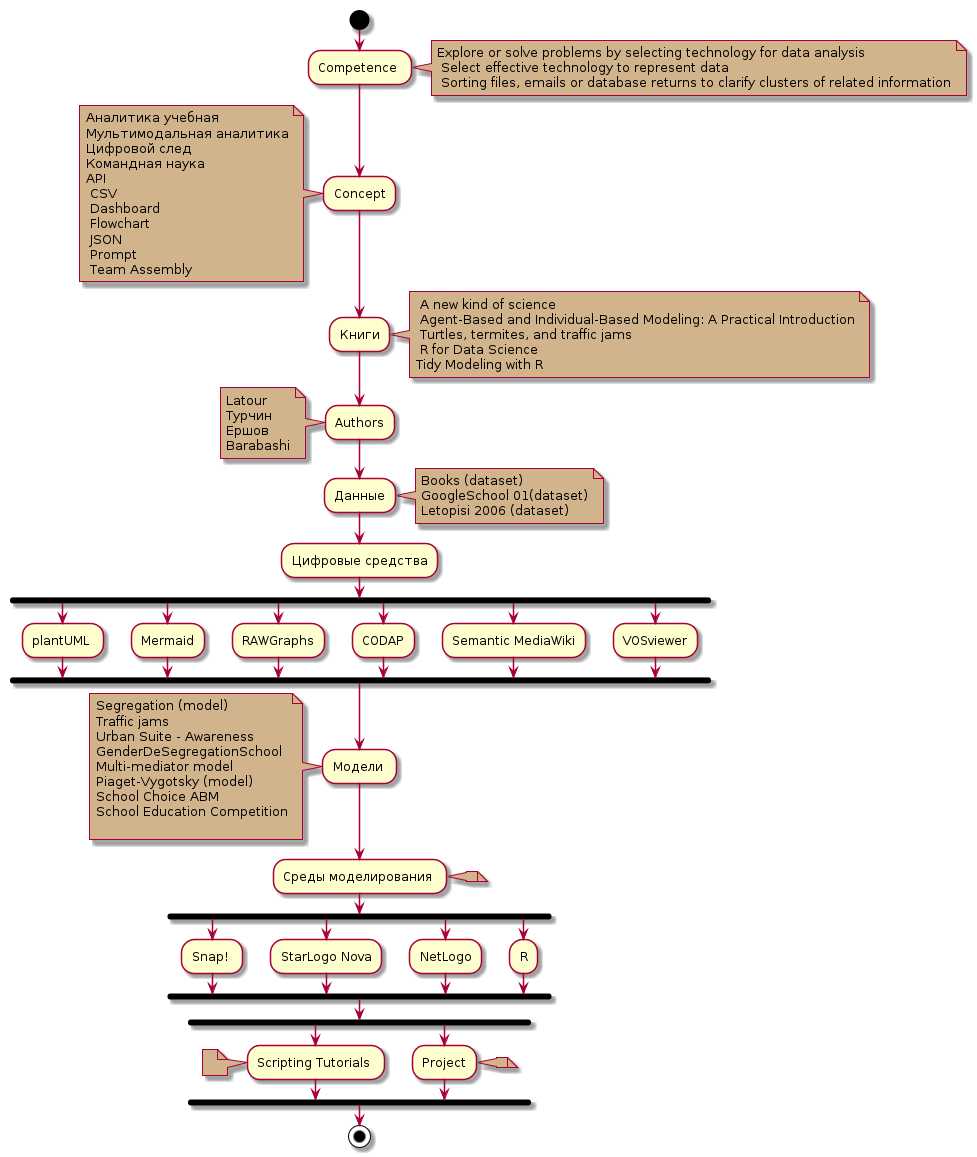
С какими данными и что мы будем делать
Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества
| Description | |
|---|---|
| Аналитика мультимодальная | Направление учебной аналитики подчёркивает, что современные цифровые средства позволяют собирать данные сразу по нескольким каналам и такое многоканальное объединение данные позволяет глубже понимать динамику обучения.
|
| Аналитика учебная | Аналитика учебная. (Learning analytics) — измерение, сбор, анализ и представление данных об учениках и их действиях с целью понимания и оптимизации учебного процесса и той среды, где это этот процесс происходит. Набор методов, позволяющих учителям и ученикам лучше понимать происходящее в учебном процессе.
|
Например, мы отправляемся в Lens и собираем там данные о мультимодальной аналитике
Собственные данные вики и их визуализация
| Страниц | Статей | Редактирований | Участников | Файлов |
|---|---|---|---|---|
| 7414 | 1887 | 46671 | 2307 | 1958 |
Библиографические данные
Zotero + ACM https://m.youtube.com/watch?v=vNvRVTWYwlw
Внешние данные
Выращивание данных
Как вырастить данные в искусственном сообществе
Многое как данные на примере Snap!
Планирование операций над данными
Планирование действий над данными при помощи UML диаграмм
Сетевые сервисы визуализации
Использование быстрых сетевых сервисов анализа и интерпретации данных – RAWGraphs, CODAP, NetBlox. Выбор способов представления данных
Задание с RAWGraphs
- Патаракин Е. Д. Выращивание и Анализ Данных в Веб Красноярск - Сибирский федеральный университет, 2021.C. 238–242.
- https://elibrary.ru/item.asp?id=46644731
- https://www.slnova.org/patarakin/projects/694467/
Обработка, очистка
Обработка, очистка и манипуляции с данными
Мы берём исходный датасет - Cities (dataset)
| Название | Страна | Население |
|---|---|---|
| Voronezh | RU | 1047549 |
| Samara | RU | 1163399 |
| Kazan | RU | 1243500 |
| Rostov-na-Donu | RU | 1130305 |
| Nizhniy Novgorod | RU | 1259013 |
| Moscow | RU | 10381222 |
| Saint Petersburg | RU | 5351935 |
| Volgograd | RU | 1013533 |
| Omsk | RU | 1172070 |
| Yekaterinburg | RU | 1495066 |
| Ufa | RU | 1120547 |
| Chelyabinsk | RU | 1202371 |
| Novosibirsk | RU | 1612833 |
| Krasnoyarsk | RU | 1090811 |
Внутри множество городов - миллионников из разных стран. И у всех координаты в виде
Пример очистки и преобразования данных:
Статистический анализ и интерпретация данных
Основные операции статистического анализа - Анализ данных
Экспорт результатов
Подготовка результатов для публикаций, создание выполняемых публикаций и динамических визуализаций
Литература
Тексты на поле вычислительной дидактики
Дополнительная литература
- Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359.
- Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112.
Критерии оценки по дисциплине
| Образовательный результат | Тема | Задание | Пример |
|---|---|---|---|
| Знает особенности типов и источников данных | Примеры источников данных | Найти, оформить, вырастить данные для дальнейшего анализа | В категории статей о датасетах Category:Dataset |
| планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | Планирование операций над данными | Создать схему цикла работы с данными | Пример |
| Умеет использовать сетевые сервисы для экспресс-анализа и интерпретации данных | Сетевые сервисы визуализации | Использовать экспресс-методы | RAWGraphs, CODAP, graphviz - примеры использования |
| Обработать и очистить данные | Обработка, очистка | Подготовить и видоизменить данные | Примеры видоизменения данных в Snap!, R, Python |
| Операции статистического анализа | Статистический анализ и интерпретация данных | Операции над собственным датасетом | Готовые датасеты Category:Dataset |
| Подготовка выполняемой публикации | Экспорт результатов | Операции над собственным датасетом | Выполняемая публикация |
Словарик курса
| Description | |
|---|---|
| CSV | CSV (от англ. Comma-Separated Values — значения, разделённые запятыми) — текстовый формат, предназначенный для представления табличных данных. Строка таблицы соответствует строке текста, которая содержит одно или несколько полей, разделенных запятыми. |
| Dashboard | Дашборд — это информационная панель, которая получает данные из других систем и отображает их в понятном виде. — «приборная панель» или «приборная доска». Дашборды бывают интерактивными и данные в нем - кликабельными. Информация из различных источников автоматически собирается, группируется и представляется на дашборде. |
| Flowchart | Блок-схема — распространённый тип схем (графических моделей), описывающих алгоритмы или процессы, в которых отдельные шаги изображаются в виде блоков различной формы, соединённых между собой линиями, указывающими направление последовательности. В вики создаются и отображаются при помощи языков graphviz, PlanUML и mermaid
 |
| JSON | JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Как и многие другие текстовые форматы, JSON легко читается людьми. Формат JSON был разработан Дугласом Крокфордом. Несмотря на то, что он очень похож на буквенный синтаксис объекта JavaScript, его можно использовать независимо от JavaScript, и многие среды программирования имеют возможность читать (анализировать) и генерировать JSON. |
| Агент | Агенты - это автономные объекты, которые могут самостоятельно реагировать на внешние события и выбирать соответствующие действия. Это - некто или нечто, выполняющий инструкции. В информатике - сущность, которая расположена в некоторой среде и способна в этой среде к автономным целенаправленным действиям. |
| Акторно-сетевая теория | Ключевое положение теории состоит в том, что участники сетей — люди — рассматриваются наравне со всеми другими сущностями, включенными в сеть. Объектом изучения акторно-сетевой теории является сеть социальных взаимодействий, неотделимая от социальных акторов. Акторно-сетевая теория обосновывает равенство всех узлов сети тем, что без других сущностей человек не может существовать ни одного мгновения. Внутри акторно-сетевой теории люди не имеют никакого преимущества перед объектами или орудиями. Отношения между людьми, вещами, медиаторами, компьютерными программами полностью симметричны. Люди, орудия и объекты рассматриваются как равные узлы гибридной сети. |
| Аналитика учебная | Аналитика учебная. (Learning analytics) — измерение, сбор, анализ и представление данных об учениках и их действиях с целью понимания и оптимизации учебного процесса и той среды, где это этот процесс происходит. Набор методов, позволяющих учителям и ученикам лучше понимать происходящее в учебном процессе.
|
| Библиографическая запись | Библиографическая запись — элемент библиографической информации, фиксирующий в документальной форме сведения о документе, позволяющие его идентифицировать, раскрыть его состав и содержание в целях библиографического поиска. |
| Выращивание данных | Data-farming - данных в ходе изучения сложных и комплексных систем с огромным количеством агентов в искусственных сообществах многоагентного моделирования/ |
| Гистограмма | Гистогра́мма (от др.-греч. ἱστός— столб + γράμμα — черта, буква, написание) — способ представления табличных данных в графическом виде — в виде столбчатой диаграммы. В описательной статистике гистограмма распределения — наглядное представление функции плотности вероятности некоторой случайной величины, построенное по выборке. Иногда её называют частотным распределением, так как гистограмма показывает частоту появления измеренных значений параметров объекта. Данное понятие и название для него введены Карлом Пирсоном в 1895 году.
 |
| Данные образовательные | Образовательные данные или данные, связанные со сферой образования, можно определить как информацию, которая собирается, хранится и анализируется с целью понимания и улучшения образовательных процессов, результатов и систем. Эти данные включают в себя:
|

