Язык программирования R (syllabus) 2026: различия между версиями
Материал из Поле цифровой дидактики
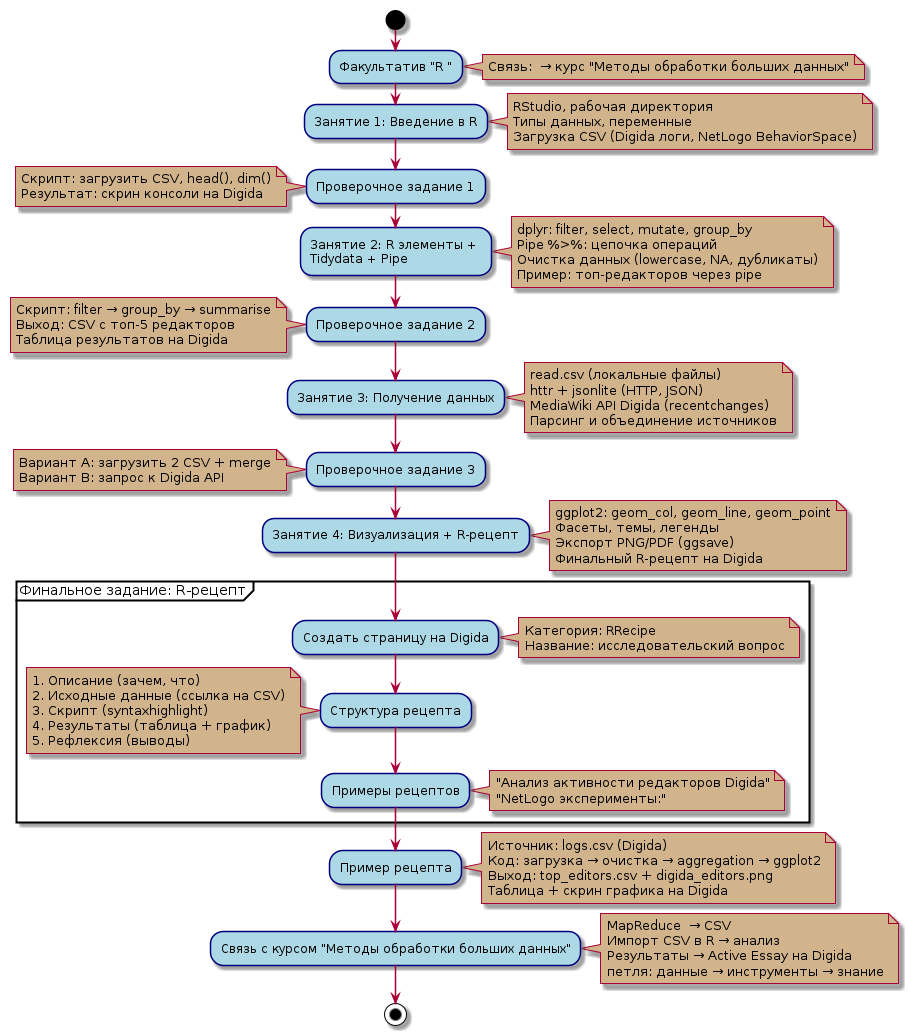
Patarakin (обсуждение | вклад) Новая страница: «{{Curriculum |Environment=R |Book=R for Data Science }} == Последовательность курса == <uml> @startuml skinparam NoteBackgroundColor tan skinparam backgroundColor white skinparam activity { BackgroundColor lightblue BorderColor navy } start :Факультатив "R для Digida Big Data"; note right 4 занятия, 1.5–2 часа каждое Связь: результаты → курс "Методы...» |
Patarakin (обсуждение | вклад) |
||
| (не показано 5 промежуточных версий этого же участника) | |||
| Строка 1: | Строка 1: | ||
{{Curriculum | {{Curriculum | ||
|Learning_outcomes=Знать | |||
* основные особенности языка R и его роль в анализе данных ; | |||
* принципы tidy data: строка = наблюдение, столбец = переменная; | |||
* базовые возможности пакетов dplyr, httr/jsonlite, ggplot2 для обработки, получения и визуализации данных; | |||
* общую схему работы с данными курса: Digida/NetLogo → CSV/API → R → визуализация → публикация на Digida. | |||
; Уметь | |||
* настраивать рабочую среду R/RStudio и загружать данные из CSV‑файлов; | |||
* выполнять базовую обработку данных в R: фильтрацию, выбор столбцов, группировку, агрегирование с помощью `%>%` и dplyr; | |||
* получать данные по HTTP и из MediaWiki API (Digida) и преобразовывать их в таблицы; | |||
* строить простые графики в ggplot2 (столбчатые, линейные, точечные) и сохранять результаты; | |||
* документировать полный рецепт обработки данных на странице Digida (код, данные, результаты, вывод). | |||
; Владеть | |||
* базовыми приёмами потоковой обработки данных в R с использованием pipe‑нотации; | |||
* навыками интеграции R‑скриптов с инфраструктурой Digida | |||
|Description=; Введение в язык R и настройка рабочей среды | |||
* обзор языка R и RStudio; | |||
* установка и выбор рабочей директории; | |||
* загрузка данных из CSV (логи Digida, результаты NetLogo); | |||
* базовые операции: просмотр данных, размер, типы столбцов. | |||
; Элементы языка программирования R и tidydata | |||
* векторы, data.frame, основы индексирования; | |||
* пакет dplyr: `filter`, `select`, `mutate`, `group_by`, `summarise`; | |||
* оператор pipe `%>%` и построение цепочек преобразований; | |||
* tidydata и приведение исходных логов/экспериментов к опрятному виду. | |||
; Получение данных из файлов, по HTTP и через MediaWiki API | |||
* повторение `read.csv` для локальных файлов (Digida/NetLogo CSV); | |||
* пакет httr: выполнение GET‑запросов; | |||
* пакет jsonlite: преобразование JSON в таблицы; | |||
* примеры запросов к MediaWiki API Digida (recentchanges и др.); | |||
* объединение данных из нескольких источников (merge/join). | |||
; Визуализация данных и R‑рецепты для Digida | |||
* базовые графики в ggplot2: `geom_col`, `geom_line`, `geom_point`; | |||
* настройка подписей, осей, тем и сохранение графиков (ggsave); | |||
* структура R‑рецепта: описание задачи, данные, код, таблицы, графики, выводы; | |||
* создание страницы в категории RRecipe на Digida с полным рецептом извлечения и анализа данных. | |||
|Environment=R | |Environment=R | ||
|Book=R for Data Science | |Book=R for Data Science | ||
}} | }} | ||
== Последовательность курса == | == Последовательность курса == | ||
| Строка 17: | Строка 55: | ||
start | start | ||
:Факультатив "R | :Факультатив "R "; | ||
note right | note right | ||
Связь: → курс "Методы обработки больших данных" | |||
Связь: | |||
end note | end note | ||
| Строка 34: | Строка 71: | ||
Скрипт: загрузить CSV, head(), dim() | Скрипт: загрузить CSV, head(), dim() | ||
Результат: скрин консоли на Digida | Результат: скрин консоли на Digida | ||
end note | end note | ||
:Занятие 2: R элементы + | :Занятие 2: R элементы + \nTidydata + Pipe; | ||
note right | note right | ||
dplyr: filter, select, mutate, group_by | dplyr: filter, select, mutate, group_by | ||
| Строка 50: | Строка 86: | ||
Выход: CSV с топ-5 редакторов | Выход: CSV с топ-5 редакторов | ||
Таблица результатов на Digida | Таблица результатов на Digida | ||
end note | end note | ||
| Строка 65: | Строка 100: | ||
Вариант A: загрузить 2 CSV + merge | Вариант A: загрузить 2 CSV + merge | ||
Вариант B: запрос к Digida API | Вариант B: запрос к Digida API | ||
end note | end note | ||
| Строка 82: | Строка 115: | ||
Категория: RRecipe | Категория: RRecipe | ||
Название: исследовательский вопрос | Название: исследовательский вопрос | ||
end note | end note | ||
| Строка 97: | Строка 129: | ||
note right | note right | ||
"Анализ активности редакторов Digida" | "Анализ активности редакторов Digida" | ||
"NetLogo эксперименты: | "NetLogo эксперименты:" | ||
end note | end note | ||
} | } | ||
| Строка 110: | Строка 141: | ||
end note | end note | ||
:Связь с курсом "Методы обработки больших данных"; | :Связь с курсом "Методы обработки больших данных"; | ||
note right | note right | ||
MapReduce | MapReduce → CSV | ||
Импорт CSV в R → анализ | Импорт CSV в R → анализ | ||
Результаты → Active Essay на Digida | Результаты → Active Essay на Digida | ||
петля: данные → инструменты → знание | |||
end note | end note | ||
| Строка 130: | Строка 155: | ||
</uml> | </uml> | ||
=== Книги === | |||
{{#ask: [[Категория:Book]] [[Description::+]] [[Environment::R]] | ?Description | ?Environment }} | |||
=== Уроки === | |||
{{#ask: [[Категория:Lesson]] [[Description::+]] [[Environment::R]] | ?Description | ?Environment }} | |||
Текущая версия от 12:55, 3 марта 2026
| Планируемые результаты обучения (Знать, Уметь, Владеть) | Знать
|
|---|---|
| Содержание разделов курса | ; Введение в язык R и настройка рабочей среды
|
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | R |
| Книги, на которых основывается учебный курс | R for Data Science |
Последовательность курса
Книги
| Description | Environment | |
|---|---|---|
| APIs for social scientists: A collaborative review | В книге представлено множество API социальных сетей и основы их использования. В статье по этой книге собраны примеры API и особенности работы с ними. Код в книге - R | R RStudio API |
| Big Data with R | Exploring, Visualizing, and Modeling Big Data with R
| R SQL Spark |
| Causal Inference in R | Welcome to Causal Inference in R. Answering causal questions is critical for scientific and business purposes, but techniques like randomized clinical trials and A/B testing are not always practical or successful. The tools in this book will allow readers to better make causal inferences with observational data with the R programming language. By its end, we hope to help you:
| R |
| Individual-Based Models of Cultural Evolution: A Step-by-Step Guide Using R | Книга показывает как создавать агентно-ориентированные модели или ABM культурной эволюции. В тексте книги используется код на языке программирования R. От очень простых моделей основных процессов культурной эволюции, таких как предвзятая передача и культурная мутация, к более сложным темам, таким как эволюция социального обучения, демографические эффекты и анализ социальных сетей. | R Ggplot |
| Interactive web-based data visualization with R, plotly, and shiny | Книга по разработке приложений в веб среде на основе языка R + Plotly + Shiny It makes heavy use of plotly for rendering graphics, but you’ll also learn about other R packages that augment a data science workflow, such as the tidyverse and shiny | R RStudio Shiny |
| Introduction to Econometrics with R | Введение в эконометрику с R - учебник по эконометрике с использованием языка R - еще на стадии совместного редактирования | R |
| Introductory Statistics for Economics | Книга "Introductory Statistics for Economics" предназначена для знакомства студентов с базовыми статистическими методами и их применением в экономике. Учебник содержит большое количество практических примеров и упражнений на языке программирования R, что формирует основные навыки данных и статистического анализа. Эти навыки отлично совмещаются с агентным моделированием в NetLogo, ведь полученные инструменты анализа данных и программирования применимы для анализа результатов симуляций и их визуализации. | R |
| Learn ggplot2 using Shiny App | Сетевая книга по освоению приемов работы с пакетом ggplot2 языка R в среде Shiny | R RStudio Shiny |
| Learning analytics methods and tutorials: A practical guide using R | Методы учебной аналитики с использованием языка R - открытое руководство с многочисленными примерами и ссылками на образовательные датасеты | R RStudio Аналитика мультимодальная |
| Mastering Shiny: Build Interactive Apps, Reports, and Dashboards Powered by R | Книга о создании аналитических веб-приложений на языке R в среде Shiny | R Shiny |
| Mastering Spark with R | Руководство как использовать Apache Spark с R. Книга поможет освоить инструменты, навыки и методы Apache Spark с R, применимые в крупномасштабной обработке данных | R Spark |
| Modeling Social Behavior: Mathematical and Agent-Based Models of Social Dynamics and Cultural Evolution | Социальные, поведенческие и когнитивные науки исторически полагались на силу слова. Слова имеют силу. Богатые аналогии могут найти отклик в умах читателей и пролить свет на тайны природы. Я говорю о вербальных теориях, описательных объяснениях сложных явлений. Большинство теорий, вероятно, более точны, чем поэтичны, но они, как правило, опираются на свойство большинства языков, согласно которому фраз могут нести в себе несколько возможных импликатур — рассмотрим, например, такие слова, как «восприятие», «категория», «идентичность», «тождественность» обучение» и даже «реакция» достаточно двусмысленны, чтобы допускать множество интерпретаций. То есть язык по своей сути (и адаптивно) расплывчат и двусмыслен. В конечном счете, это проблема для ученых, потому что нам нужно предельно четко понимать, о чем мы говорим, чтобы выдвинуть полезные теории Вселенной. | NetLogo BehaviorSpace R ODD принципы Центральная предельная теорема |
| Outstanding User Interfaces with Shiny | A book about deeply customizing Shiny app for production. | R Shiny |
| R for Data Science | Подробное руководство по использованию языка R для обработки, модификации, визуализации и программировании данных. Книга "R for Data Science" вводит концепцию tidy data как стандарт организации данных, где каждая переменная — в отдельном столбце, а каждая наблюдение — в отдельной строке. Это упрощает анализ, визуализацию и моделирование с помощью tidyverse. Стратегия книги строится вокруг полного цикла data science: импорт данных, их приведение к tidy-форме (tidying), трансформация (wrangling), визуализация (ggplot2). Цель — научить думать о данных как о tidy, чтобы 80% времени уходило на анализ, а не на чистку. | Анализ данных R RStudio |
| Text Mining with R | Книга даёт завершённую картину современных аналитических подходов к тексту, систематизируя инструменты R и методику работы с данными на всех этапах анализа. | R Tidytext |
| Text Mining with R: A Tidy Approach | Практический современный учебник с фокусом на подход "tidy data" в R. Охватывает: предобработку, токенизацию, анализ тональности, тематическое моделирование, визуализацию Используемые пакеты: tidytext, dplyr, ggplot2, quanteda | R Tidytext |
| Tidy Modeling with R | Руководство по созданию и использованию моделей при помощи пакетов из пространства tidyverse: recipes, parsnip, workflows, yardstick, and others. | R RStudio R for Data Science |
| Классификация, регрессия и другие алгоритмы Data Mining с использованием R | Описана широкая совокупность методов построения статистических моделей классификации и регрессии для откликов, измеренных в альтернативной, категориальной и метрической шкалах. Подробно рассматриваются деревья решений, машины опорных векторов с различными разделяющими поверхностями, нелинейные формы дискриминантного анализа, искусственные нейронные сети и т.д. | R |
| Незримый колледж МЭШ | Статья, в которой понятие незримого колледжа применяется к сообществу учителей, сотрудничающих внутри репозитория московской электронной школы. | NetLogo BehaviorSpace R RStudio |
Уроки
| Description | Environment | |
|---|---|---|
| Pivot в R | Pivot в R (из пакета tidyr) — это "поворот" или "сводка данных", простыми словами — инструмент для перестройки формы таблицы: из длинной (long) в широкую (wide) и наоборот. Представьте, что данные — это пластилин: pivot_longer "растягивает" таблицу вниз, превращая столбцы в строки, а pivot_wider "расплющивает" её в стороны, делая из строк новые столбцы. Это нужно, чтобы привести данные к tidy-стандарту для удобного анализа, графиков и моделей — в образовании часто данные приходят "криво" (оценки по предметам в столбцах или в строках), а pivot их быстро приводит в порядок. | R |
| Как извлечь данные из категории Digida | Мы хотим проанализировать тексты, которые хранятся в статья определенной категории поля цифровой дидактики. Есть 2 способа - экспорт статей и использование MediaWiki API | Semantic MediaWiki R MediaWiki API |
| Как изучить данные PISA learningtower package | Некоторые данные PISA доступны в сети и в среде пакетов R. Например, можно использовать learningtower package | R |
| Как изучить студию с помощью Scratch API | Мы хотим изучить деятельность участников, которые разместили свои проекты внутри конкретной студии Scratch. В этом рецепте мы изучаем как авторы размещают свои проекты в данной студии (по ее номеру) и в других студиях. При этом исходно мы не использовали данные о комментариях к студии и проектам. | NetLogo R VOSviewer Scratch API |
| Как посчитать метрики командности (GitLab) | У нас есть записи коммитов в GitLab и мы хотим оценить командность действий участников в различных проектах | R GitLab |
| Как представить графы совместной деятельности в R | Для датасета из GitLab строим графы месячной активности участников. | R RStudio |
| Как провести поверхностный анализ текста | Поверхностный анализ текста — это анализ легко измеримых, формальных характеристик текста, которые не требуют глубокого лингвистического анализа или интерпретации смысла. К ним относятся:
| R VOYANT Tools |
| Как провести семантический анализ текста |
| R |
| Как провести сравнительный анализ поведения на поле цифровой дидактики (R) | Мы собрали датасет о действиях участников на площадке digida и хотим провести анализ этого датасета с демонстрацией возможностей среды R
| R Digida2026 |
| Сравнение Scratch wikis | Это рецепт извлечения данных по MediaWiki API из различных вики площадок, связанных с языком программирования Scratch. | Scratch R MediaWiki API Песочница MediaWiki API |
| Сравнить тексты нескольких датасетов | У нас есть несколько датасетов с библиографическими данными. Мы хотим провести сравнительный анализ по столбцу названий публикаций, чтобы понять различия между научными школами | GitHub R Lens VOYANT Tools Lens Psych Collab |
| Считать данные в R | Как считать данные в R, если они лежат на локальной машине или доступны удаленно по URL | GitHub R |


