Обработка больших данных (syllabus): различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| (не показано 15 промежуточных версий этого же участника) | |||
| Строка 1: | Строка 1: | ||
{{Curriculum | {{Curriculum | ||
|Environment=R, RStudio, NetLogo | |Learning_outcomes=Готовность студентов к профессиональной деятельности, связанной с обработкой и анализом больших данных, в педагогической сфере. | ||
|Book=R for Data Science, Mastering Shiny: Build Interactive Apps | ; Знать | ||
# основные понятиям и термины в области обработки больших данных | |||
# методы сбора, выращивания, хранения и обработки больших данных. | |||
# методов анализа больших данных | |||
# инструменты визуализации данных для представления и интерпретации результатов анализа | |||
; Уметь | |||
# Собирать данные с полей учебной и исследовательской деятельности | |||
# Выращивать данные в искусственных средах. Ставить эксперименты с данными | |||
# Обрабатывать данные | |||
# | |||
# | |||
|Description=# Данные - основные понятия | |||
# Источники данных (где искать) | |||
## Примеры образовательных датасетов | |||
# Инструменты анализа и визуализации данных | |||
# Среды выращивания данных | |||
|Environment=R, RStudio, NetLogo, Snap!, Google Data Studio, Shiny, Python, CODAP | |||
|Book=R for Data Science, Mastering Shiny: Build Interactive Apps, Tidy Modeling with R | |||
}} | }} | ||
== Основные понятия == | |||
[[Большие данные]], [[База данных]], [[База знаний]], [[Веб-скрепинг]], [[Датасет]], [[Озеро данных]], [[Агентное моделирование]], [[Гигантская компонента]] | |||
* см. [[:Категория:Понятие]] | |||
== Источники данных == | |||
* см. [[:Категория:Dataset]] | |||
== Инструменты анализа и визуализации данных == | |||
{{#ask: [[Категория:DigitalTool]] [[Tool is made for::аналитика]] | ?Description | ?Affordances }} | |||
* библиотек [[Python]] для обработки и визуализации данных, таких как Pandas, NumPy, Matplotlib, Seaborn и Plotly | |||
== Выращивание данных при помощи многоагентных моделей == | |||
http://digida.mgpu.ru/images/thumb/5/56/Piage_Vyg.png/120px-Piage_Vyg.png | |||
{{#ask: [[Категория:Book]] [[Environment::NetLogo]] | ?Inventor | ?Description }} | |||
* https://snap.berkeley.edu/snap/snap.html#present:Username=patarakin&ProjectName=Flocking_Snap | |||
<snap project="Flocking_Snap" user="patarakin" /> | |||
{{#widget:iframe | |||
|url=https://netlogoweb.org/launch#https://netlogoweb.org/assets/modelslib/Sample%20Models/Biology/Flocking.nlogo | |||
|width=800 | |||
|height=600 | |||
}} | |||
* см. [[:Категория:Model]] | |||
== Обработка данных == | |||
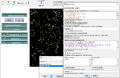
[[Файл:Khurmanenok result pic.png|400px]] | |||
== Семинары и конференции МГПУ про данные в образовании == | |||
[[Data_in_Education_Seminar|Семинар о данных в образовании]] | |||
Текущая версия на 17:42, 29 августа 2023
| Планируемые результаты обучения (Знать, Уметь, Владеть) | Готовность студентов к профессиональной деятельности, связанной с обработкой и анализом больших данных, в педагогической сфере.
|
|---|---|
| Содержание разделов курса |
|
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | R, RStudio, NetLogo, Snap!, Google Data Studio, Shiny, Python, CODAP |
| Книги, на которых основывается учебный курс | R for Data Science, Mastering Shiny: Build Interactive Apps, Tidy Modeling with R |
Основные понятия
Большие данные, База данных, База знаний, Веб-скрепинг, Датасет, Озеро данных, Агентное моделирование, Гигантская компонента
Источники данных
Инструменты анализа и визуализации данных
| Description | Affordances | |
|---|---|---|
| Biblioshiny | Пакет R для анализа библиометрических данных. Запускается как веб-страница из R - R-studio:
| Проводить библиометрический анализ с использованием возможностей языка R, но без необходимости писать текст команд |
| CODAP | Инструмент визуализации данных проведения статистических исследований на основе данных. Данные - есть готовые наборы данных, либо можно получить данные из игр и моделей.
| Пользователь может загрузить набор данных из набора данных или просто перетащить их мышкой из своей таблицы в таблицу CODAP.
|
| CODAP API | API for CODAP | |
| Chronoviz | ChronoViz is a tool to aid visualization and analysis of multimodal sets of time-coded information, with a focus on the analysis of video in combination with other data sources. | Анализ мультимодальной информации - видео + другие источники In comparison to other data visualization tools, ChronoViz is unique in its focus on time-coded multimodal data and its ability to integrate with various data sources. It offers a range of visualization techniques and navigation mechanisms, making it a powerful tool for researchers working with time-based data. |
| Frequency Distribution Analysis Library | Библиотека анализа распределения значений внутри данных. Библиотека Snap!
| Расчёт и и построение графиков распределения той или иной величины на экране - функции группировки и сортировки значений. |
| Jamovi | ||
| Kepler | Open Source инструмента для визуализации и анализа больших наборов гео-данных.
 | На сегодняшний день Kepler.gl поддерживает 3 формата исходных данных: geojson, json и csv. Сохранив данные в одном указанных форматов просто загружаем их в приложение. |
| Mathematica | Mathematica — проприетарная система компьютерной алгебры, широко используемая для научных, инженерных, математических расчётов. Разработана в 1988 году Стивеном Вольфрамом, дальнейшим развитием системы занята основанная им совместно с Теодором Греем компания Wolfram Research. | Оснащена как аналитическими возможностями, так и обеспечивает численные расчёты; результаты выводятся как в алфавитно-цифровом виде, так и в форме графиков. |
| MediaWiki API | Движок MediaWiki имеет свой API, который является веб-службой, обеспечивающей доступ к многим функциям вики. Благодаря этому инструменту мы можем собирать информацию с любой из внешних вики площадок. | аутентификация, операции над страницами, поиск по вики и множество других операций. MediaWiki API может обрабатывать запросы через обработчик(скрипт) api.php, который написан на языке программирования PHP. Обработчик принимает запросы через отправку HTTP запросов на адрес(url) обработчика.
|
| Network Workbench | Network Workbench: A Large-Scale Network Analysis, Modeling and Visualization Toolkit for Biomedical, Social Science and Physics Research.This project will design, evaluate, and operate a unique distributed, shared resources environment for large-scale network analysis, modeling, and visualization, named Network Workbench (NWB). | |
| Postman | Postman — это сервис для создания, тестирования, документирования, публикации и обслуживания API. | Сервис позволяет создавать коллекции запросов к любому API, применять к ним разные окружения, настраивать мок-серверы, писать автотесты на JavaScript, анализировать и визуализировать результаты запросов.
|
| Scratch API | Инструмент доступа к данным сообщества Scratch | Получать информацию о действиях отдельных участников, активности в студиях, активности по отдельным проектам |
| ShinyItemAnalysis | R пакет для он-лайн психометрического анализа образовательных тестов | можно использовать собственные наборы данных или использовать готовые наборы |
| Tableau | Tableau - BI-система, предназначенная для анализа и визуализации данных. Интерфейс разработан таким образом, чтобы было несложно разобраться, даже если вы никогда раньше не создавали дашборды. Позволяет создавать интерактивные и обновляемые в режиме реального времени панели, в том числе – на основе совмещенных данных. | Плюсы Tableau:
поддерживает более 30 типов данных; один из самых простых для освоения инструментов бизнес-аналитики; много обучающей информации в текстовом и видеоформате; развивается и регулярно обновляется. |
| VOSviewer | VOSviewer — это программа для построения и визуализации библиометрических сетей. |
|
| Web Scraper | Надстройка для Chrome. Инструмент для извлечения данных из веб-страниц | Сэкономить время на ручном поиске и однотипных данных (текста, ссылок, данных из таблиц, адресов электронной почты и тд) и выгрузить итоговый результат в CSV |
| Песочница MediaWiki API | Инструмент позволяет подбирать параметры для запроса к MediaWiki API | Разные действия в запросе:
|
| Якласс | Образовательный портал | Организация дистанционных занятий, размещение учебных материалов, посещение вебинаров, ведение оценочной деятельности |
- библиотек Python для обработки и визуализации данных, таких как Pandas, NumPy, Matplotlib, Seaborn и Plotly
Выращивание данных при помощи многоагентных моделей
| Inventor | Description | |
|---|---|---|
| Agent-Based and Individual-Based Modeling: A Practical Introduction | Railsback Grimm | Подробное руководство по дизайну экспериментов в среде Netlogo с использованием BehaviorSpace и использованием ODD принципов
|
| An Introduction to Agent-Based Modeling: Modeling Natural, Social, and Engineered Complex Systems with NetLogo | Wilensky Rand | Введение в моделирование систем при помощи языка NetLogo (от создателя языка) - использование NetLogo в естественно-научном, инженерном и общественном образовании |
| Growing Artificial Societies: Social Science From the Bottom Up (Complex Adaptive Systems) | Epstein Axtell | Первая книга о выращивании искусственных сообществ. В книге представлена модель Sugarscape - простое искусственное общество, в котором агенты живут на двухмерной сетке и взаимодействуют друг с другом на основе правил, регулирующих передвижение, размножение и торговлю. Модель Sugarscape служит основой для изучения различных социальных явлений, таких как возникновение распределения богатства, передача культуры, сотрудничество и конфликты.
 |
| Modeling Social Behavior: Mathematical and Agent-Based Models of Social Dynamics and Cultural Evolution | Smaldino | Социальные, поведенческие и когнитивные науки исторически полагались на силу слова. Слова имеют силу. Богатые аналогии могут найти отклик в умах читателей и пролить свет на тайны природы. Я говорю о вербальных теориях, описательных объяснениях сложных явлений. Большинство теорий, вероятно, более точны, чем поэтичны, но они, как правило, опираются на свойство большинства языков, согласно которому фраз могут нести в себе несколько возможных импликатур — рассмотрим, например, такие слова, как «восприятие», «категория», «идентичность», «тождественность» обучение» и даже «реакция» достаточно двусмысленны, чтобы допускать множество интерпретаций. То есть язык по своей сути (и адаптивно) расплывчат и двусмыслен. В конечном счете, это проблема для ученых, потому что нам нужно предельно четко понимать, о чем мы говорим, чтобы выдвинуть полезные теории Вселенной. |
| Thinking Like a Tree | Resnick | Thinking Like a Tree (and Other Forms of Ecological Thinking ) Мы можем сказать, что дерево следует стратегии TREE - T- test - пробуй, R - randomly - случайно, E-evaluate - оценивай (определяй, какие из корней нашли лучшую почву), E-elect - выбирай (направление, куда будем двигаться). Конечно, шагающее дерево в действительности не выбирает и не принимает решение, куда двигаться. Но, этот способ размышления о дереве, следующем определенной стратегии поведения, может оказаться полезным. |
| Turtles, termites, and traffic jams: explorations in massively parallel microworld | Resnick | Книга "Черепахи, термиты и дорожные пробки: исследования в микромире массово-параллельных вычислений" Децентрализованный подход к феноменам окружающего мира - на основе использования микромира с тысячами черепашек |
| Незримый колледж МЭШ | Patarakin | Статья, в которой понятие незримого колледжа применяется к сообществу учителей, сотрудничающих внутри репозитория московской электронной школы. |
- см. Категория:Model
Обработка данных
