Как изучить студию с помощью Scratch API: различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) Нет описания правки |
Patarakin (обсуждение | вклад) Нет описания правки |
||
| Строка 375: | Строка 375: | ||
) | ) | ||
} | } | ||
############################################################ | |||
# 0. Вспомогательная функция: безопасный GET с JSON | |||
############################################################ | |||
safe_get_json <- function(url, verbose = TRUE) { | |||
if (verbose) message("GET ", url) | |||
resp <- GET(url) | |||
if (status_code(resp) != 200) return(NULL) | |||
txt <- content(resp, as = "text", encoding = "UTF-8") | |||
if (identical(txt, "") || is.null(txt)) return(NULL) | |||
out <- fromJSON(txt, flatten = TRUE) | |||
out | |||
} | |||
###-------- | |||
get_studio_comments <- function(studio_id, | |||
limit = 40, | |||
max_pages = 200, | |||
verbose = TRUE) { | |||
offset <- 0 | |||
page <- 1 | |||
all <- list() | |||
repeat { | |||
if (page > max_pages) break | |||
url <- paste0( | |||
"https://api.scratch.mit.edu/studios/", | |||
studio_id, | |||
"/comments?limit=", limit, | |||
"&offset=", offset | |||
) | |||
dat <- safe_get_json(url, verbose = verbose) | |||
if (is.null(dat) || length(dat) == 0) break | |||
all[[length(all) + 1]] <- dat | |||
if (nrow(dat) < limit) break | |||
offset <- offset + limit | |||
page <- page + 1 | |||
} | |||
if (length(all) == 0) return(NULL) | |||
res <- bind_rows(all) | |||
res |> | |||
transmute( | |||
studio_id = studio_id, | |||
comment_id = id, | |||
parent_id = if ("parent_id" %in% names(res)) parent_id else NA, | |||
author_id = `author.id`, | |||
author_username = `author.username`, | |||
content = content, | |||
datetime_created = lubridate::as_datetime(datetime_created), | |||
datetime_modified = lubridate::as_datetime(datetime_modified), | |||
visibility = visibility, | |||
reply_count = reply_count | |||
) | |||
} | |||
###---- | |||
get_project_comments <- function(username, | |||
project_id, | |||
limit = 40, | |||
max_pages = 200, | |||
verbose = TRUE) { | |||
offset <- 0 | |||
page <- 1 | |||
all <- list() | |||
user_name <- as.character(username)[1] | |||
repeat { | |||
if (page > max_pages) break | |||
url <- paste0( | |||
"https://api.scratch.mit.edu/users/", | |||
user_name, | |||
"/projects/", | |||
project_id, | |||
"/comments?limit=", limit, | |||
"&offset=", offset | |||
) | |||
dat <- safe_get_json(url, verbose = verbose) | |||
if (is.null(dat) || length(dat) == 0) break | |||
all[[length(all) + 1]] <- dat | |||
if (nrow(dat) < limit) break | |||
offset <- offset + limit | |||
page <- page + 1 | |||
} | |||
if (length(all) == 0) return(NULL) | |||
res <- bind_rows(all) | |||
res |> | |||
transmute( | |||
project_id = project_id, | |||
project_owner = user_name, | |||
comment_id = id, | |||
parent_id = if ("parent_id" %in% names(res)) parent_id else NA, | |||
author_id = `author.id`, | |||
author_username = `author.username`, | |||
content = content, | |||
datetime_created = lubridate::as_datetime(datetime_created), | |||
datetime_modified = lubridate::as_datetime(datetime_modified), | |||
visibility = visibility, | |||
reply_count = reply_count | |||
) | |||
} | |||
######-------------------------------- | |||
get_all_project_comments_for_studio <- function(studio_id, | |||
studio_projects, | |||
verbose = TRUE) { | |||
if (is.null(studio_projects) || nrow(studio_projects) == 0) return(NULL) | |||
# Оставляем только нужные поля | |||
sp <- studio_projects |> | |||
transmute( | |||
project_id, | |||
project_owner = username | |||
) |> | |||
distinct() | |||
all_comments <- purrr::map2_df( | |||
sp$project_owner, | |||
sp$project_id, | |||
~ { | |||
if (verbose) message("Project ", .y, " (owner: ", .x, ")") | |||
get_project_comments(.x, .y, verbose = verbose) | |||
} | |||
) | |||
if (nrow(all_comments) == 0) return(NULL) | |||
all_comments |> | |||
mutate( | |||
studio_id = studio_id, | |||
.before = 1 | |||
) | |||
} | |||
</syntaxhighlight> | |||
=== Анализ отношений между авторами и студиями === | |||
<syntaxhighlight lang="R" line> | |||
############################################### | ############################################### | ||
| Строка 494: | Строка 651: | ||
vertex.label = NA, | vertex.label = NA, | ||
edge.color = "grey80") | edge.color = "grey80") | ||
</syntaxhighlight> | |||
=== Анализ комментариев к студиям и проектам === | |||
<syntaxhighlight lang="R" line> | |||
analyze_studio_comments <- function(studio_id, | |||
studio_projects, | |||
verbose = TRUE) { | |||
# 4.1. Комментарии в студии | |||
studio_comments <- get_studio_comments(studio_id, verbose = verbose) | |||
# 4.2. Комментарии ко всем проектам студии | |||
project_comments <- get_all_project_comments_for_studio( | |||
studio_id = studio_id, | |||
studio_projects = studio_projects, | |||
verbose = verbose | |||
) | |||
# Если нет комментариев, возвращаем только то, что есть | |||
if (is.null(studio_comments) && is.null(project_comments)) { | |||
warning("Нет комментариев ни в студии, ни в проектах.") | |||
return(NULL) | |||
} | |||
# 4.3. Авторские составы | |||
# — кто пишет в студии, кто в проектах, кто в обоих | |||
authors_studio <- studio_comments |> | |||
distinct(author_username) |> | |||
mutate(where = "studio") | |||
authors_projects <- project_comments |> | |||
distinct(author_username) |> | |||
mutate(where = "projects") | |||
authors_all <- bind_rows(authors_studio, authors_projects) |> | |||
group_by(author_username) |> | |||
summarise( | |||
in_studio = "studio" %in% where, | |||
in_projects = "projects" %in% where, | |||
.groups = "drop" | |||
) | |||
# 4.4. Частоты комментариев по авторам | |||
studio_author_freq <- studio_comments |> | |||
count(author_username, name = "studio_comments") |> | |||
arrange(desc(studio_comments)) | |||
project_author_freq <- project_comments |> | |||
count(author_username, name = "project_comments") |> | |||
arrange(desc(project_comments)) | |||
# 4.5. Простые текстовые показатели | |||
# длина комментария в символах | |||
studio_text_stats <- studio_comments |> | |||
mutate( | |||
n_chars = nchar(content, allowNA = TRUE) | |||
) | |||
project_text_stats <- project_comments |> | |||
mutate( | |||
n_chars = nchar(content, allowNA = TRUE) | |||
) | |||
# 4.6. Динамика по времени (по месяцам) | |||
studio_time <- studio_comments |> | |||
mutate(month = floor_date(datetime_created, "month")) |> | |||
count(month, name = "studio_comments") |> | |||
arrange(month) | |||
project_time <- project_comments |> | |||
mutate(month = floor_date(datetime_created, "month")) |> | |||
count(month, name = "project_comments") |> | |||
arrange(month) | |||
# 4.7. Собираем результаты для дальнейшей визуализации / анализа | |||
res <- list( | |||
studio_comments = studio_comments, | |||
project_comments = project_comments, | |||
authors_overlap = authors_all, | |||
studio_author_freq = studio_author_freq, | |||
project_author_freq = project_author_freq, | |||
studio_text_stats = studio_text_stats, | |||
project_text_stats = project_text_stats, | |||
studio_time = studio_time, | |||
project_time = project_time | |||
) | |||
# 4.8. Простые сводные метрики для интерпретации | |||
# Авторские роли | |||
n_authors_total <- nrow(authors_all) | |||
n_only_studio <- sum(authors_all$in_studio & !authors_all$in_projects) | |||
n_only_proj <- sum(!authors_all$in_studio & authors_all$in_projects) | |||
n_both <- sum(authors_all$in_studio & authors_all$in_projects) | |||
share_only_studio <- n_only_studio / n_authors_total | |||
share_only_proj <- n_only_proj / n_authors_total | |||
share_both <- n_both / n_authors_total | |||
# Средняя длина комментариев (в символах) | |||
mean_len_studio <- mean(studio_text_stats$n_chars, na.rm = TRUE) | |||
mean_len_project <- mean(project_text_stats$n_chars, na.rm = TRUE) | |||
# Топ-авторы в студии и в проектах (по числу комментариев) | |||
top_studio_authors <- studio_author_freq |> | |||
head(10) | |||
top_project_authors <- project_author_freq |> | |||
head(10) | |||
res$summary_metrics <- list( | |||
n_authors_total = n_authors_total, | |||
n_only_studio = n_only_studio, | |||
n_only_projects = n_only_proj, | |||
n_both = n_both, | |||
share_only_studio = share_only_studio, | |||
share_only_projects = share_only_proj, | |||
share_both = share_both, | |||
mean_len_studio = mean_len_studio, | |||
mean_len_project = mean_len_project, | |||
top_studio_authors = top_studio_authors, | |||
top_project_authors = top_project_authors | |||
) | |||
res | |||
} | |||
</syntaxhighlight> | </syntaxhighlight> | ||
Версия от 08:19, 24 марта 2026
| Описание | Мы хотим изучить деятельность участников, которые разместили свои проекты внутри конкретной студии Scratch |
|---|---|
| Область знаний | Информатика, Статистика, Моделирование |
| Область использования (ISTE) | |
| Возрастная категория | 14
|
| Поясняющее видео | |
| Близкие рецепту понятия | Социограмма, Сетевой анализ |
| Среды и средства для приготовления рецепта: | R, Scratch API, VOSviewer, NetLogo |
История
В среде Scratch есть студии, которые объединяют проекты разных скретчеров. Мы хотим изучить отношения авторов этой студии, используя возможности Scratch API

Последовательность исследования
Логика сбора данных
- Perplexy.AI
- PlantUML
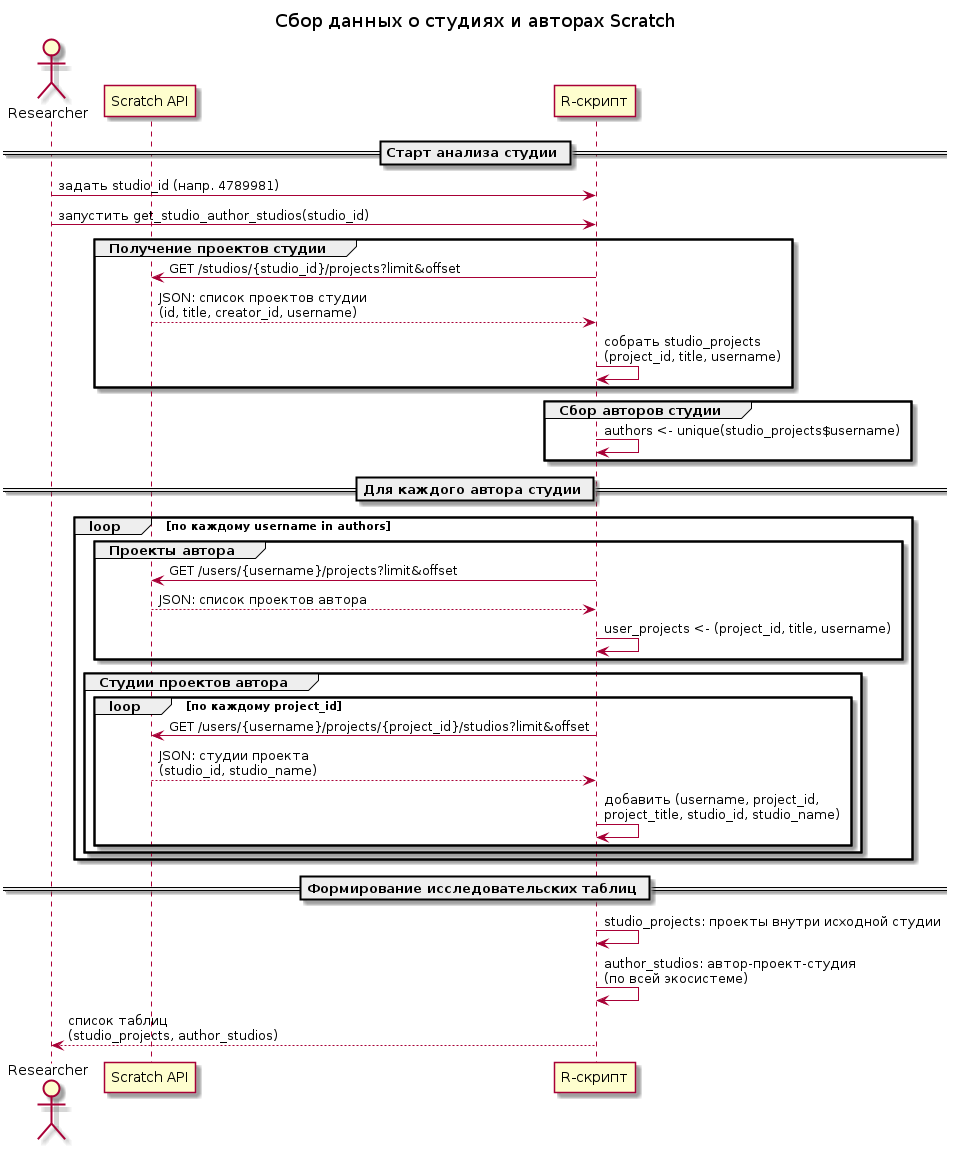
Логика исследования
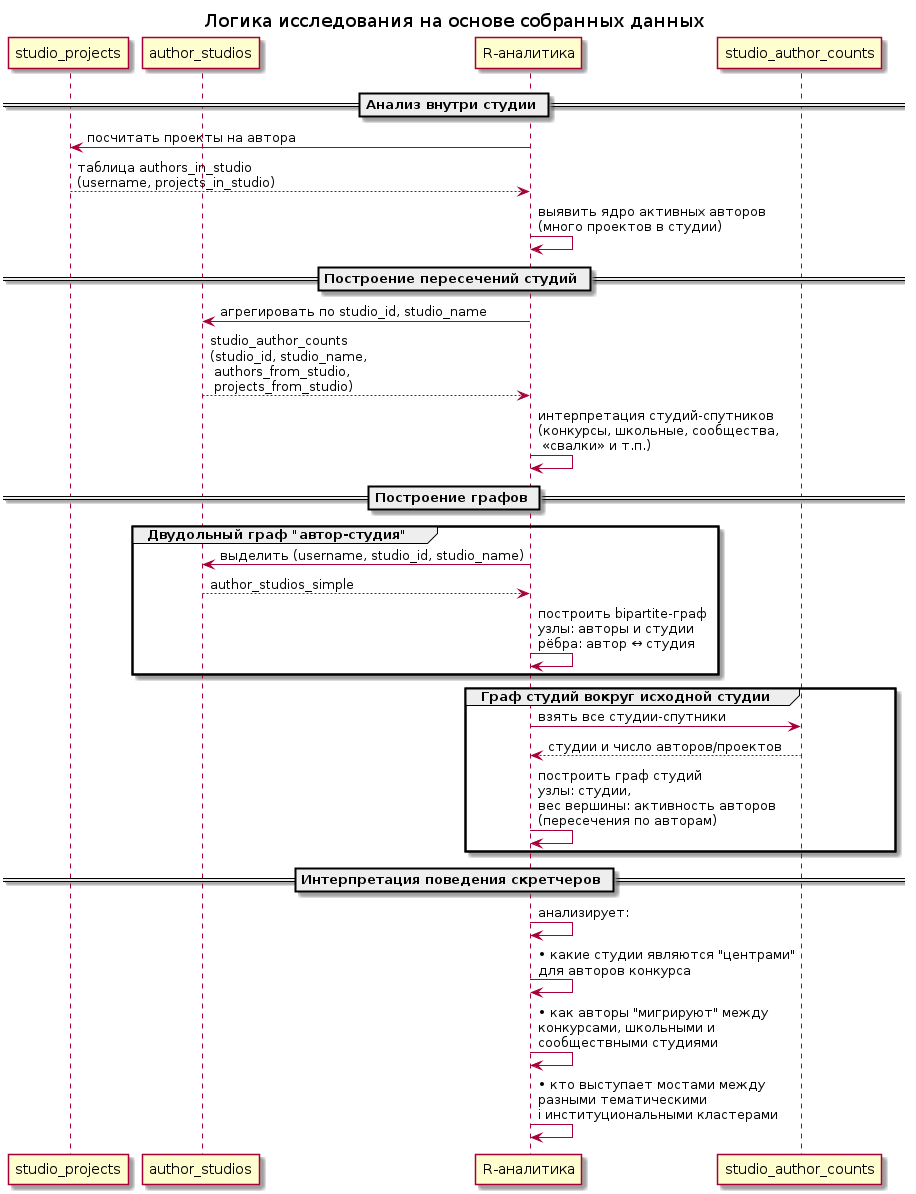
В результате мы получаем два слоя данных — внутренний срез конкурсной студии (кто и с какими проектами участвует) и внешний слой окружения этих авторов (в какие ещё студии они выкладывают свои проекты). Это позволяет видеть не только «жизнь внутри конкурса», но и более широкие траектории участия скретчеров в сообществе.
R скрипт сбора данных
###############################################
# Анализ авторов и студий Scratch на R
# (пример на студии 4789981 — Collab Challenge)
###############################################
# Пакеты ----
library(httr)
library(jsonlite)
library(dplyr)
library(purrr)
library(tidyr)
library(igraph)
###############################################
# 1. Функция для получения проектов студии
###############################################
# Использует API:
# https://api.scratch.mit.edu/studios/<studio_id>/projects?limit=&offset=
# Возвращает data.frame:
# project_id, title, creator_id, username
get_studio_projects <- function(studio_id, limit = 40, verbose = TRUE) {
offset <- 0
all_projects <- list()
page <- 1
repeat {
url <- paste0(
"https://api.scratch.mit.edu/studios/",
studio_id,
"/projects?limit=", limit,
"&offset=", offset
)
if (verbose) message("Studio ", studio_id,
": page ", page,
" (offset = ", offset, ")")
resp <- GET(url)
if (status_code(resp) != 200) {
warning("Non-200 status code: ", status_code(resp),
" at offset ", offset)
break
}
txt <- content(resp, as = "text", encoding = "UTF-8")
dat <- fromJSON(txt, flatten = TRUE)
if (length(dat) == 0) break
all_projects[[length(all_projects) + 1]] <- dat
if (nrow(dat) < limit) break
offset <- offset + limit
page <- page + 1
}
if (length(all_projects) == 0) return(NULL)
bind_rows(all_projects) |>
transmute(
project_id = id,
title = title,
creator_id = creator_id,
username = username
) |>
distinct()
}
###############################################
# 2. Проекты пользователя
###############################################
# API:
# https://api.scratch.mit.edu/users/<username>/projects?limit=&offset=
# Возвращает data.frame:
# project_id, title, username
get_user_projects <- function(username, limit = 40, max_pages = 10, verbose = TRUE) {
offset <- 0
all <- list()
page <- 1
repeat {
if (page > max_pages) break
url <- paste0(
"https://api.scratch.mit.edu/users/",
username,
"/projects?limit=", limit,
"&offset=", offset
)
if (verbose) message("User ", username,
": page ", page,
" (offset = ", offset, ")")
resp <- GET(url)
if (status_code(resp) != 200) break
txt <- content(resp, as = "text", encoding = "UTF-8")
dat <- fromJSON(txt, flatten = TRUE)
if (length(dat) == 0) break
all[[length(all) + 1]] <- dat
if (nrow(dat) < limit) break
offset <- offset + limit
page <- page + 1
}
if (length(all) == 0) return(NULL)
res <- bind_rows(all)
res |>
transmute(
project_id = id,
title = title,
username = username # аргумент функции
) |>
distinct()
}
###############################################
# 3. Студии одного проекта пользователя
###############################################
# ВАЖНО: используем путь:
# https://api.scratch.mit.edu/users/<username>/projects/<project_id>/studios
# а не /projects/<id>/studios, потому что второй вариант
# часто не работает.
#
# Возвращает data.frame:
# studio_id, studio_name
###############################################
get_project_studios <- function(username, project_id,
limit = 40, max_pages = 10,
verbose = TRUE) {
user_name <- as.character(username)[1]
offset <- 0
all <- list()
page <- 1
repeat {
if (page > max_pages) break
url <- paste0(
"https://api.scratch.mit.edu/users/",
user_name,
"/projects/",
project_id,
"/studios?limit=", limit,
"&offset=", offset
)
if (verbose) {
message("User ", user_name,
", project ", project_id,
": page ", page,
" (offset = ", offset, ")")
}
resp <- GET(url)
if (status_code(resp) != 200) {
return(NULL)
}
txt <- content(resp, as = "text", encoding = "UTF-8")
dat <- fromJSON(txt, flatten = TRUE)
if (length(dat) == 0) break
all[[length(all) + 1]] <- dat
if (nrow(dat) < limit) break
offset <- offset + limit
page <- page + 1
}
if (length(all) == 0) return(NULL)
res <- bind_rows(all)
if (!("id" %in% names(res)) || !("title" %in% names(res))) return(NULL)
res |>
transmute(
studio_id = id,
studio_name = title
) |>
distinct()
}
###############################################
# 4. Автор → его проекты → студии этих проектов
###############################################
# Возвращает data.frame:
# username, project_id, project_title, studio_id, studio_name
get_user_project_studios <- function(username, verbose = TRUE) {
user_projects <- get_user_projects(username, verbose = verbose)
if (is.null(user_projects) || nrow(user_projects) == 0) return(NULL)
proj_studios <- user_projects |>
mutate(
studios = map(
project_id,
~ get_project_studios(username, .x, verbose = verbose)
)
)
proj_studios_nonempty <- proj_studios |>
filter(!map_lgl(studios, is.null))
if (nrow(proj_studios_nonempty) == 0) return(NULL)
proj_studios_nonempty |>
tidyr::unnest(cols = studios) |>
transmute(
username,
project_id,
project_title = title,
studio_id,
studio_name
) |>
distinct()
}
###############################################
# 5. От студии → к авторам → к студиям авторов
###############################################
# Возвращает список:
# $studio_projects — проекты внутри исходной студии
# $author_studios — студии, где встречаются проекты её авторов
get_studio_author_studios <- function(studio_id, verbose = TRUE) {
# Проекты студии
studio_projects <- get_studio_projects(studio_id, verbose = verbose)
if (is.null(studio_projects) || nrow(studio_projects) == 0) return(NULL)
# Авторы этих проектов
authors <- unique(studio_projects$username)
# Для каждого автора — его проекты и студии этих проектов
author_studios <- purrr::map_df(
authors,
~ {
if (verbose) message("Author: ", .x)
get_user_project_studios(.x, verbose = verbose)
}
)
list(
studio_projects = studio_projects,
author_studios = author_studios
)
}
############################################################
# 0. Вспомогательная функция: безопасный GET с JSON
############################################################
safe_get_json <- function(url, verbose = TRUE) {
if (verbose) message("GET ", url)
resp <- GET(url)
if (status_code(resp) != 200) return(NULL)
txt <- content(resp, as = "text", encoding = "UTF-8")
if (identical(txt, "") || is.null(txt)) return(NULL)
out <- fromJSON(txt, flatten = TRUE)
out
}
###--------
get_studio_comments <- function(studio_id,
limit = 40,
max_pages = 200,
verbose = TRUE) {
offset <- 0
page <- 1
all <- list()
repeat {
if (page > max_pages) break
url <- paste0(
"https://api.scratch.mit.edu/studios/",
studio_id,
"/comments?limit=", limit,
"&offset=", offset
)
dat <- safe_get_json(url, verbose = verbose)
if (is.null(dat) || length(dat) == 0) break
all[[length(all) + 1]] <- dat
if (nrow(dat) < limit) break
offset <- offset + limit
page <- page + 1
}
if (length(all) == 0) return(NULL)
res <- bind_rows(all)
res |>
transmute(
studio_id = studio_id,
comment_id = id,
parent_id = if ("parent_id" %in% names(res)) parent_id else NA,
author_id = `author.id`,
author_username = `author.username`,
content = content,
datetime_created = lubridate::as_datetime(datetime_created),
datetime_modified = lubridate::as_datetime(datetime_modified),
visibility = visibility,
reply_count = reply_count
)
}
###----
get_project_comments <- function(username,
project_id,
limit = 40,
max_pages = 200,
verbose = TRUE) {
offset <- 0
page <- 1
all <- list()
user_name <- as.character(username)[1]
repeat {
if (page > max_pages) break
url <- paste0(
"https://api.scratch.mit.edu/users/",
user_name,
"/projects/",
project_id,
"/comments?limit=", limit,
"&offset=", offset
)
dat <- safe_get_json(url, verbose = verbose)
if (is.null(dat) || length(dat) == 0) break
all[[length(all) + 1]] <- dat
if (nrow(dat) < limit) break
offset <- offset + limit
page <- page + 1
}
if (length(all) == 0) return(NULL)
res <- bind_rows(all)
res |>
transmute(
project_id = project_id,
project_owner = user_name,
comment_id = id,
parent_id = if ("parent_id" %in% names(res)) parent_id else NA,
author_id = `author.id`,
author_username = `author.username`,
content = content,
datetime_created = lubridate::as_datetime(datetime_created),
datetime_modified = lubridate::as_datetime(datetime_modified),
visibility = visibility,
reply_count = reply_count
)
}
######--------------------------------
get_all_project_comments_for_studio <- function(studio_id,
studio_projects,
verbose = TRUE) {
if (is.null(studio_projects) || nrow(studio_projects) == 0) return(NULL)
# Оставляем только нужные поля
sp <- studio_projects |>
transmute(
project_id,
project_owner = username
) |>
distinct()
all_comments <- purrr::map2_df(
sp$project_owner,
sp$project_id,
~ {
if (verbose) message("Project ", .y, " (owner: ", .x, ")")
get_project_comments(.x, .y, verbose = verbose)
}
)
if (nrow(all_comments) == 0) return(NULL)
all_comments |>
mutate(
studio_id = studio_id,
.before = 1
)
}
Анализ отношений между авторами и студиями
###############################################
# 6. Пример: анализ студии 4789981
###############################################
# 6.1. Собираем данные
res_4789981 <- get_studio_author_studios(4789981, verbose = TRUE)
studio_projects <- res_4789981$studio_projects
author_studios <- res_4789981$author_studios
# 6.2. Активность авторов внутри студии:
authors_in_4789981 <- studio_projects |>
count(username, name = "projects_in_studio") |>
arrange(desc(projects_in_studio))
head(authors_in_4789981)
# 6.3. Пересечения студий по авторам и проектам:
studio_author_counts <- author_studios |>
group_by(studio_id, studio_name) |>
summarise(
authors_from_4789981 = n_distinct(username),
projects_from_4789981 = n_distinct(project_id),
.groups = "drop"
) |>
arrange(desc(authors_from_4789981))
head(studio_author_counts, 20)
###############################################
# 7. Построение двудольного графа автор–студия
###############################################
# Узлы: авторы и студии.
# Рёбра: автор ↔ студия (если хотя бы один проект автора в студии).
author_studios_simple <- author_studios |>
distinct(username, studio_id, studio_name)
# Узлы-авторы
author_nodes <- author_studios_simple |>
distinct(name = username) |>
mutate(
type = "author",
label = name
)
# Узлы-студии
studio_nodes <- author_studios_simple |>
distinct(
studio_id,
studio_name
) |>
transmute(
name = as.character(studio_id),
type = "studio",
label = studio_name
)
nodes <- bind_rows(author_nodes, studio_nodes)
# Рёбра: автор → студия
edges <- author_studios_simple |>
transmute(
from = username,
to = as.character(studio_id)
)
# Граф
g_bip <- graph_from_data_frame(
d = edges,
vertices = nodes,
directed = FALSE
)
# Простейший просмотр структуры:
g_bip
vcount(g_bip)
ecount(g_bip)
table(V(g_bip)$type)
###############################################
# 8. Экспорт nodes и edges в CSV
# (для VOSviewer, NetLogo, Gephi и др.)
###############################################
nodes_export <- tibble(
id = V(g_bip)$name,
type = V(g_bip)$type,
label = V(g_bip)$label
)
edges_export <- as_data_frame(g_bip, what = "edges") |>
as_tibble() |>
rename(
from = from,
to = to
)
write.csv(nodes_export,
"scratch_studios_nodes.csv",
row.names = FALSE,
fileEncoding = "UTF-8")
write.csv(edges_export,
"scratch_studios_edges.csv",
row.names = FALSE,
fileEncoding = "UTF-8")
###############################################
# 9. Простая визуализация в R
###############################################
# Быстрый "черновой" рисунок:
plot(g_bip,
vertex.size = ifelse(V(g_bip)$type == "studio", 6, 3),
vertex.color = ifelse(V(g_bip)$type == "studio", "tomato", "skyblue"),
vertex.label = NA,
edge.color = "grey80")
Анализ комментариев к студиям и проектам
analyze_studio_comments <- function(studio_id,
studio_projects,
verbose = TRUE) {
# 4.1. Комментарии в студии
studio_comments <- get_studio_comments(studio_id, verbose = verbose)
# 4.2. Комментарии ко всем проектам студии
project_comments <- get_all_project_comments_for_studio(
studio_id = studio_id,
studio_projects = studio_projects,
verbose = verbose
)
# Если нет комментариев, возвращаем только то, что есть
if (is.null(studio_comments) && is.null(project_comments)) {
warning("Нет комментариев ни в студии, ни в проектах.")
return(NULL)
}
# 4.3. Авторские составы
# — кто пишет в студии, кто в проектах, кто в обоих
authors_studio <- studio_comments |>
distinct(author_username) |>
mutate(where = "studio")
authors_projects <- project_comments |>
distinct(author_username) |>
mutate(where = "projects")
authors_all <- bind_rows(authors_studio, authors_projects) |>
group_by(author_username) |>
summarise(
in_studio = "studio" %in% where,
in_projects = "projects" %in% where,
.groups = "drop"
)
# 4.4. Частоты комментариев по авторам
studio_author_freq <- studio_comments |>
count(author_username, name = "studio_comments") |>
arrange(desc(studio_comments))
project_author_freq <- project_comments |>
count(author_username, name = "project_comments") |>
arrange(desc(project_comments))
# 4.5. Простые текстовые показатели
# длина комментария в символах
studio_text_stats <- studio_comments |>
mutate(
n_chars = nchar(content, allowNA = TRUE)
)
project_text_stats <- project_comments |>
mutate(
n_chars = nchar(content, allowNA = TRUE)
)
# 4.6. Динамика по времени (по месяцам)
studio_time <- studio_comments |>
mutate(month = floor_date(datetime_created, "month")) |>
count(month, name = "studio_comments") |>
arrange(month)
project_time <- project_comments |>
mutate(month = floor_date(datetime_created, "month")) |>
count(month, name = "project_comments") |>
arrange(month)
# 4.7. Собираем результаты для дальнейшей визуализации / анализа
res <- list(
studio_comments = studio_comments,
project_comments = project_comments,
authors_overlap = authors_all,
studio_author_freq = studio_author_freq,
project_author_freq = project_author_freq,
studio_text_stats = studio_text_stats,
project_text_stats = project_text_stats,
studio_time = studio_time,
project_time = project_time
)
# 4.8. Простые сводные метрики для интерпретации
# Авторские роли
n_authors_total <- nrow(authors_all)
n_only_studio <- sum(authors_all$in_studio & !authors_all$in_projects)
n_only_proj <- sum(!authors_all$in_studio & authors_all$in_projects)
n_both <- sum(authors_all$in_studio & authors_all$in_projects)
share_only_studio <- n_only_studio / n_authors_total
share_only_proj <- n_only_proj / n_authors_total
share_both <- n_both / n_authors_total
# Средняя длина комментариев (в символах)
mean_len_studio <- mean(studio_text_stats$n_chars, na.rm = TRUE)
mean_len_project <- mean(project_text_stats$n_chars, na.rm = TRUE)
# Топ-авторы в студии и в проектах (по числу комментариев)
top_studio_authors <- studio_author_freq |>
head(10)
top_project_authors <- project_author_freq |>
head(10)
res$summary_metrics <- list(
n_authors_total = n_authors_total,
n_only_studio = n_only_studio,
n_only_projects = n_only_proj,
n_both = n_both,
share_only_studio = share_only_studio,
share_only_projects = share_only_proj,
share_both = share_both,
mean_len_studio = mean_len_studio,
mean_len_project = mean_len_project,
top_studio_authors = top_studio_authors,
top_project_authors = top_project_authors
)
res
}
Данные студии
Ребра
| От кого | К кому |
|---|---|
| timur1985 | 4789981 |
| timur1985 | 33969674 |
| timur1985 | 36279833 |
Узлы
Визуализация
VOSviewer
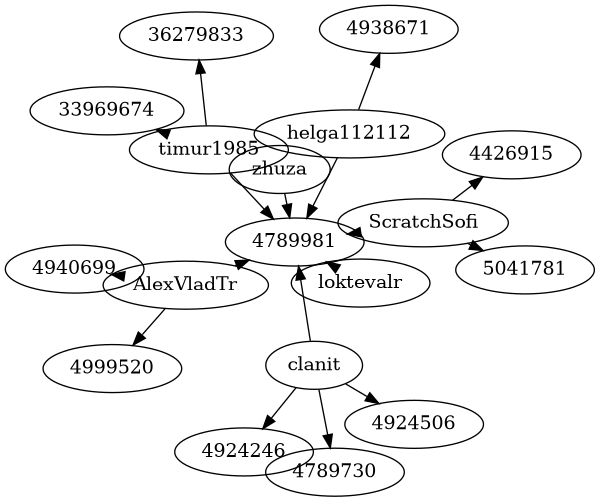
Симуляция в NetLogo
| Description | |
|---|---|
| Биграф | Биграф. Двудо́льный граф или бигра́ф или bipartite graph — это математический термин теории графов, обозначающий граф, множество вершин которого можно разбить на две части таким образом, что каждое ребро графа соединяет какую-то вершину из одной части с какой-то вершиной другой части, то есть не существует ребра, соединяющего две вершины из одной и той же части. |
| Социограмма | Социограмма — способ представления, межличностных и межгрупповых отношений в виде системы связей (графа) между индивидами или социальными группами. Анализ социограммы начинается с отыскания центральных, наиболее влиятельных членов, затем взаимных пар и группировок. |
Модели на собранных данных
| Description | |
|---|---|
| DigidaCollab 02 2026 | Датасет включающий только совместные редактирования статей авторами на площадке Digida |
| Lens Psych Collab | Lens Psych Collab - This NetLogo model visualizes the evolution of scientific authorship networks using real publication data from Lens.org. The model tracks the dynamics of collaboration patterns among psychologists from major Russian academic institutions: Moscow City University (MCU), Lomonosov Moscow State University (MSU), and the Russian Academy of Sciences. The model simulates how scientific collaboration networks grow and evolve over time by processing publications chronologically, creating author agents, establishing co-authorship links, and updating network metrics in real-time. It helps researchers understand how new authors enter the scientific community, how experienced researchers maintain collaborations, and how network structure emerges from individual collaboration decisions. |
| Preferential Attachment | Модель предпочтительного присоединения - Preferential Attachment - Процесс предпочтительного присоединения - это любой из классов процессов, в которых некоторое количество, обычно некоторое форма богатства или кредита распределяется между несколькими людьми или объектами в зависимости от того, сколько они уже имеют, так что те, кто уже богат, получают больше, чем те, кто не богат. «Предпочтительная привязанность» - это лишь последнее из многих названий, которые были даны таким процессам. Они также упоминаются как «богатые становятся богаче». Процесс предпочтительного присоединения генерирует распределение «с длинным хвостом » после распределения Парето или степенной закон в его хвосте. Это основная причина исторического интереса к предпочтительной привязанности: распределение видов и многие другие явления наблюдаются эмпирически, следуя степенным законам, и процесс предпочтительной привязанности является ведущим механизмом для объяснения этого поведения. Предпочтительное прикрепление считается возможным основанием для распределения размеров городов, богатства чрезвычайно богатых людей, количества цитирований, полученных научными публикациями, и количества ссылок на страницы во всемирной паутине.
|

Код модели
extensions [resource csv]
breed [users user] ;
breed [pages page] ;
directed-link-breed [bonds bond] ;
users-own [agentname] ;
pages-own [
pagename
] ;
bonds-own [edits] ;
globals [
backgroud
data
current-wiki ;; "DE" "/ FR / RU / EN / JP
]
to startup
clear-all ;
reset-ticks
set-default-shape users "person" ;
set-default-shape pages "square" ;
set current-wiki wiki_lng_chooser
output-print "" ;
set data [] ;
output-print "╔════════════════════════════════════════════════════════════╗"
output-print "║Scratch Studio Simulation ║"
output-print "╚════════════════════════════════════════════════════════════╝"
output-print ""
;; output-print (word "Выберите источник данных (Wiki_Chooser): " current-wiki)
output-print "После выбора нажмите кнопку 'Сеть авторов'."
end
to load-data-for-current-wiki
load-csv-resource "scratch_studios4789981_edges.csv"
end
to load-csv-resource [filename]
set data []
output-print ""
output-print (word "Загрузка файла: " filename)
carefully [
let csv-content resource:get filename
set data csv:from-string csv-content
output-print (word "Загружен: " length data " строк (с заголовком)")
] [
output-print (word "ОШИБКА при загрузке " filename ": " error-message)
stop
]
if length data > 0 [
set data but-first data
]
output-print (word "Обработано " length data " публикаций из " filename)
end
to load_data
clear-turtles
clear-output ;
clear-all-plots ;
output-print "История совместного редактирования статей" ;
output-print "Scratch Wikis" ;
load-data-for-current-wiki
;; set data csv:from-string csv-content
foreach data [ ?1 -> visual ?1 ]
end
to visual [flist]
;; output-print flist ;
let agent_name item 0 flist ;; это мы просто считали имена агентов и страниц
let page_name item 1 flist
ifelse (not any? users with [agentname = agent_name]) and (not any? pages with [pagename = page_name])
[
create-ordered-users 1 [
set size 0.7
set color red
set agentname agent_name ;
set label-color white
set label agentname ;
output-print agentname
hatch-pages 1 [
set pagename page_name
set color green
set label-color white
set label pagename create-bond-from myself ;
ask bond [who] of myself [who] of self
;;
[
set edits 1
set label-color white
; set label edits
]
output-print ( word " -> " pagename )
output-print "" ;
] ; ;
]
]
[ ifelse (not any? users with [agentname = agent_name]) and (any? pages with [pagename = page_name])
[
let myfirstpage [who] of one-of pages with [pagename = page_name] ;
ask page myfirstpage [
hatch-users 1
[
set color red set agentname agent_name
set label-color white
output-print agentname
set label agentname create-bond-to myself ;
output-print (word " -> " page_name )
output-print "" ;
ask bond [who] of self myfirstpage
[
;;set edits 1
;; set label-color white
;; set label edits
]
]
]
]
;; у нас есть юзер, но нет страницы
[ ifelse (any? users with [agentname = agent_name]) and (not any? pages with [pagename = page_name])
[
let author [who] of one-of users with [agentname = agent_name] ;
output-print agent_name ;
ask user author [hatch-pages 1
[ set color green set pagename page_name
set label-color white set label pagename
create-bond-from myself
output-print ( word " -> " pagename )
output-print "" ;
] ;; ask bond [who] of myself myfirstpage [set edits 1]
;
]
]
;; Ситуация, когда есть и пользователь и страница - и там варианты с тем, что есть связь или нет связи
[
let author [who] of one-of users with [agentname = agent_name] ;
let mypage [who] of one-of pages with [pagename = page_name] ;
ifelse is-link? bond author mypage [ask bond author mypage
[set edits edits + 1 set label edits
]
]
[
ask user author [
create-bond-to page mypage
]
ask bond author mypage [
;; set edits 1 set label edits
]
]
; ask bond author mypage [set edits edits + 1 set label edits] ;
];; Если есть и страница и агент, то надо просто увеличить значение связи
]] ;
layout
update-plots
end
to layout
layout-spring turtles links 0.2 0.04 0.7
display
end

