R for Data Science: различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) Нет описания правки |
Patarakin (обсуждение | вклад) м Patarakin переименовал страницу Уроки/R for Data Science в R for Data Science поверх перенаправления и без оставления перенаправления: Откат |
||
| (не показано 26 промежуточных версий 2 участников) | |||
| Строка 1: | Строка 1: | ||
{{Book | {{Book | ||
|Description=Подробное руководство по использованию языка R для обработки, модификации, визуализации и программировании данных | |Description=Подробное руководство по использованию языка R для обработки, модификации, визуализации и программировании данных. Книга "'''R for Data Science'''" вводит концепцию tidy data как стандарт организации данных, где каждая переменная — в отдельном столбце, а каждая наблюдение — в отдельной строке. Это упрощает анализ, визуализацию и моделирование с помощью tidyverse. Стратегия книги строится вокруг полного цикла data science: импорт данных, их приведение к tidy-форме (tidying), трансформация (wrangling), визуализация (ggplot2). Цель — научить думать о данных как о tidy, чтобы 80% времени уходило на анализ, а не на чистку. | ||
|Field_of_knowledge=NetSci, Биология, Информатика, Социология | |Field_of_knowledge=NetSci, Биология, Информатика, Социология | ||
|launch year=2023 | |launch year=2023 | ||
|Website=https://r4ds.hadley.nz/ | |Website=https://r4ds.hadley.nz/ | ||
|Clarifying_video=https://www.youtube.com/watch?v=go5Au01Jrvs | |Clarifying_video=https://www.youtube.com/watch?v=go5Au01Jrvs | ||
|Environment=R, RStudio | |Inventor=Wickham | ||
|Environment=R, RStudio, Анализ_данных | |||
}} | }} | ||
=== Book WorkFlow === | |||
<uml> | |||
@startuml | |||
skinparam NoteBackgroundColor tan | |||
start | |||
:Import; | |||
note right | |||
csv | |||
Web scraping | |||
end note | |||
:Tidy; | |||
note left | |||
tidyverse | |||
mutate | |||
group_by | |||
summarize | |||
end note | |||
:Transform; | |||
note right | |||
filter | |||
mutate | |||
summarize | |||
if_else() | |||
case_when() | |||
Regular expressions | |||
end note | |||
:Visualize; | |||
note left | |||
ggplot | |||
ggplot2 | |||
ggthemes | |||
glimpse | |||
end note | |||
:Communicate; | |||
note right | |||
end note | |||
stop | |||
@enduml | |||
</uml> | |||
=== Особенности книги === | |||
* Тема моделирования с [[R]] в редакции 2023 года из книги удалена - советуют [[Tidy Modeling with R]] | |||
Сама книга опубликована на [[Quarto]] и является примером для таких понятий как [[активное эссе]] и [[выполняемая публикация]] | |||
=== Уроки из [[R for Data Science]] === | |||
Tidy data обеспечивает единообразную структуру, совместимую с функциями tidyverse. Основные принципы: переменные в столбцах, наблюдения в строках; одна [[таблица]] на [[датасет]]. Это позволяет R работать с векторами естественно, ускоряя трансформации. | |||
{{#ask: [[Pivot в R]] | ?Description }} | |||
Текущая версия от 17:57, 31 мая 2026
| Описание книги | Подробное руководство по использованию языка R для обработки, модификации, визуализации и программировании данных. Книга "R for Data Science" вводит концепцию tidy data как стандарт организации данных, где каждая переменная — в отдельном столбце, а каждая наблюдение — в отдельной строке. Это упрощает анализ, визуализацию и моделирование с помощью tidyverse. Стратегия книги строится вокруг полного цикла data science: импорт данных, их приведение к tidy-форме (tidying), трансформация (wrangling), визуализация (ggplot2). Цель — научить думать о данных как о tidy, чтобы 80% времени уходило на анализ, а не на чистку. |
|---|---|
| Область знаний | NetSci, Биология, Информатика, Социология |
| Год издания | 2023 |
| Веб-сайт где можно прочитать книгу или статью | https://r4ds.hadley.nz/ |
| Видео запись | https://www.youtube.com/watch?v=go5Au01Jrvs |
| Авторы | Wickham |
| Среды и средства, на которые повлияла книга | R, RStudio, Анализ_данных |
Book WorkFlow
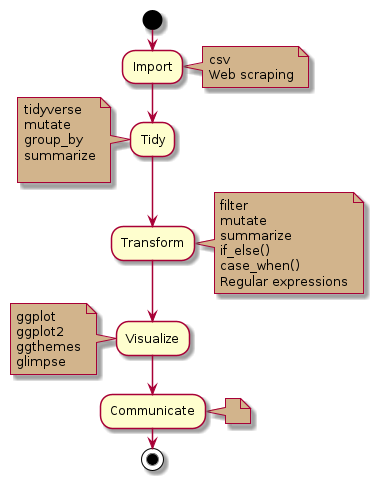
Особенности книги
- Тема моделирования с R в редакции 2023 года из книги удалена - советуют Tidy Modeling with R
Сама книга опубликована на Quarto и является примером для таких понятий как активное эссе и выполняемая публикация
Уроки из R for Data Science
Tidy data обеспечивает единообразную структуру, совместимую с функциями tidyverse. Основные принципы: переменные в столбцах, наблюдения в строках; одна таблица на датасет. Это позволяет R работать с векторами естественно, ускоряя трансформации.
| Description | |
|---|---|
| Pivot в R | Pivot в R (из пакета tidyr) — это "поворот" или "сводка данных", простыми словами — инструмент для перестройки формы таблицы: из длинной (long) в широкую (wide) и наоборот. Представьте, что данные — это пластилин: pivot_longer "растягивает" таблицу вниз, превращая столбцы в строки, а pivot_wider "расплющивает" её в стороны, делая из строк новые столбцы. Это нужно, чтобы привести данные к tidy-стандарту для удобного анализа, графиков и моделей — в образовании часто данные приходят "криво" (оценки по предметам в столбцах или в строках), а pivot их быстро приводит в порядок. |

