Анализ и интерпретация данных (syllabus): различия между версиями
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| (не показано 40 промежуточных версий этого же участника) | |||
| Строка 1: | Строка 1: | ||
{{Curriculum | |||
|Learning_outcomes=В результате освоения дисциплины слушатель должен: | |||
; Знать | |||
* особенности типов и источников данных | |||
; Уметь: | |||
* планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML диаграмм (plantUML, MerMaid) | |||
* использовать сетевые сервисы для экспресс-анализа и интерпретации данных (RAWGraphs) | |||
* очищать, обрабатывать и видоизменять данные, приводя их к опрятному виду tidy data (Snap!, R) | |||
* совершать операции статистического анализа | |||
; Владеть: | |||
* навыками выстраивания процесс анализа и интерпретации данных от исходных сырых данных до публикации отчета или статьи | |||
* навыками выращивания данных в искусственных сообществах (NetLogo, GAMA) | |||
|Description=Разделы: | |||
# Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества | |||
# Планирование операций над данными | |||
# Блочные сервисы визуализации данных | |||
# Блочные языки обработки и представления данных | |||
|Environment=BehaviorSpace, NetLogo, Scratch, Snap!, Сообщество Scratch, CODAP, RStudio, RAWGraphs | |||
}} | |||
== Составляющие курса == | |||
=== Составляющие поля совместной деятельности === | |||
<graphviz> | <graphviz> | ||
digraph Digida1 { | digraph Digida1 { | ||
| Строка 24: | Строка 45: | ||
} | } | ||
</graphviz> | </graphviz> | ||
=== UML диаграмма - последовательность учебного курса === | |||
; | <uml> | ||
@startuml | |||
; | skinparam NoteBackgroundColor tan | ||
start | |||
:Competence ; | |||
note right | |||
Explore or solve problems by selecting technology for data analysis | |||
; | Select effective technology to represent data | ||
Sorting files, emails or database returns to clarify clusters of related information | |||
end note | |||
:Concept; | |||
note left | |||
Learning Analytics | |||
API | |||
CSV | |||
Dashboard | |||
Flowchart | |||
JSON | |||
Prompt | |||
Team Assembly | |||
end note | |||
:Book; | |||
note right | |||
A new kind of science | |||
Agent-Based and Individual-Based Modeling: A Practical Introduction | |||
Turtles, termites, and traffic jams | |||
R for Data Science | |||
Tidy Modeling with R | |||
end note | |||
:Authors; | |||
note left | |||
Latour | |||
Tourchin | |||
Barabashi | |||
end note | |||
:Data; | |||
note right | |||
Books (dataset) | |||
GoogleSchool 01(dataset) | |||
Letopisi 2006 (dataset) | |||
end note | |||
:Digital tool; | |||
fork | |||
:plantUML ; | |||
fork again | |||
:Mermaid; | |||
fork again | |||
:RAWGraphs; | |||
fork again | |||
:CODAP; | |||
fork again | |||
:Semantic MediaWiki; | |||
end fork | |||
:Model ; | |||
note left | |||
Segregation (model) | |||
Traffic jams | |||
Urban Suite - Awareness | |||
end note | |||
:Programming Language ; | |||
note right | |||
end note | |||
fork | |||
:Snap! ; | |||
fork again | |||
:StarLogo Nova; | |||
fork again | |||
:NetLogo; | |||
fork again | |||
:R; | |||
end fork | |||
fork | |||
:Scripting Tutorials ; | |||
note left | |||
end note | |||
fork again | |||
:Project; | |||
note right | |||
end note | |||
end fork | |||
stop | |||
@enduml | |||
</uml> | |||
== С какими данными и что мы будем делать == | |||
Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества | |||
=== | === Собственные данные вики и их визуализация === | ||
; [[Dashboard]] | |||
{| class="wikitable" | |||
! Страниц | |||
! Статей | |||
! Редактирований | |||
! Участников | |||
! Файлов | |||
{{!}}- | |||
{{!}} {{NUMBEROFPAGES:R}} | |||
{{!}} {{NUMBEROFARTICLES:R}} | |||
{{!}} {{NUMBEROFEDITS:R}} | |||
{{!}} {{NUMBEROFUSERS:R}} | |||
{{!}} {{NUMBEROFFILES}} | |||
|} | |||
---- | |||
{{#ask: [[Категория:DigitalTool]] [[Tool_is_made_for::+]] | |||
|?Tool_is_made_for | |||
|mainlabel=- | |||
|format=jqplotchart | |||
|charttype=bar | |||
|height= 600 | |||
|filling=1 | |||
|distribution= yes | |||
|min = 1 | |||
|width=100% | |||
|direction=horizontal | |||
|theme=simple | |||
|colorscheme=rdbu | |||
}} | |||
==== | ==== Библиографические данные ==== | ||
[https://app.vosviewer.com/?json=https://drive.google.com/uc?id=1vYgqSwG2d1X3RyNDt1AA_mDRIDo0B2ZG Пример работы] | |||
= | [[Zotero]] + ACM https://m.youtube.com/watch?v=vNvRVTWYwlw | ||
[[Библиографический датасет 1]] | |||
== Внешние данные == | |||
# https://corgis-edu.github.io/corgis/ | |||
## https://corgis-edu.github.io/corgis/csv/graduates/ | |||
#### https://corgis-edu.github.io/corgis/datasets/csv/graduates/graduates.csv | |||
См. [[:Категория:Dataset]] | |||
== Выращивание данных == | |||
[[Как вырастить данные в искусственном сообществе]] | |||
==== Многое как данные на примере Snap! ==== | ==== Многое как данные на примере Snap! ==== | ||
| Строка 85: | Строка 208: | ||
=== Планирование операций над данными === | === Планирование операций над данными === | ||
Планирование действий над данными при помощи UML диаграмм | Планирование действий над данными при помощи UML диаграмм | ||
[[:Категория:Diagrams]] | |||
=== Сетевые сервисы визуализации === | === Сетевые сервисы визуализации === | ||
| Строка 91: | Строка 217: | ||
==== Задание с [[RAWGraphs]] ==== | ==== Задание с [[RAWGraphs]] ==== | ||
; Патаракин Е. Д. Выращивание и Анализ Данных в Веб Красноярск | ; Патаракин Е. Д. Выращивание и Анализ Данных в Веб Красноярск - Сибирский федеральный университет, 2021.C. 238–242. | ||
: https://elibrary.ru/item.asp?id=46644731 | : https://elibrary.ru/item.asp?id=46644731 | ||
: https://www.slnova.org/patarakin/projects/694467/ | : https://www.slnova.org/patarakin/projects/694467/ | ||
=== Обработка, очистка === | === Обработка, очистка === | ||
Обработка, очистка и манипуляции с данными в пакетах R и Python – использование tidyverse & tidygraph | Обработка, очистка и манипуляции с данными | ||
* В [[Snap!]] | |||
* в пакетах [[R]] и [[Python]] – использование tidyverse & tidygraph | |||
Мы берём исходный [[датасет]] - [[Cities (dataset)]] | |||
{{#get_web_data:url=http://www.uic.unn.ru/pustyn/data-sets/digida/Millions_Cities.csv | |||
|format=csv with header | |||
|filters=Country Code=RU | |||
|data=Name=Name,Country=Country Code,Population=Population,Coordinates=Coordinates | |||
}} | |||
{| class="wikitable sortable" | |||
! Название | |||
! Страна | |||
! Население {{#for_external_table:<nowiki/> | |||
{{!}}- | |||
{{!}} {{{Name}}} | |||
{{!}}{{{Country}}} | |||
{{!}} {{{Population}}} }} | |||
|} | |||
Внутри множество городов - миллионников из разных стран. И у всех координаты в виде | |||
Пример очистки и преобразования данных: | |||
* https://snap.berkeley.edu/snap/snap.html#present:Username=patarakin&ProjectName=BigCities | |||
<snap project="BigCities" user="patarakin" /> | |||
=== Статистический анализ и интерпретация данных === | === Статистический анализ и интерпретация данных === | ||
Основные операции статистического анализа | Основные операции статистического анализа - [[Анализ данных]] | ||
=== Экспорт результатов === | === Экспорт результатов === | ||
| Строка 106: | Строка 259: | ||
== Литература == | == Литература == | ||
=== | |||
=== Тексты на поле вычислительной дидактики === | |||
=== Дополнительная литература === | === Дополнительная литература === | ||
# Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359. | # Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359. | ||
# Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112. | # Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112. | ||
== Видеоматериалы == | == Видеоматериалы == | ||
| Строка 127: | Строка 281: | ||
| Примеры источников данных | | Примеры источников данных | ||
| Найти, оформить, вырастить данные для дальнейшего анализа | | Найти, оформить, вырастить данные для дальнейшего анализа | ||
| В категории статей о датасетах | | В категории статей о датасетах [[:Category:Dataset]] | ||
|- | |- | ||
| планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | | планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | ||
| Планирование операций над данными | | Планирование операций над данными | ||
| Создать схему цикла работы с данными | | Создать схему цикла работы с данными | ||
| Пример [[:Category:Diagrams]] | | Пример | ||
* [[:Category:Diagrams]] | |||
* [[Диаграмма_профиля_компетенций]] | |||
* [[Диаграмма формирования компетентного профиля]] | |||
* [[Диаграмма Ганта]] | |||
|- | |- | ||
| Умеет использовать сетевые сервисы для экспресс-анализа и интерпретации данных | | Умеет использовать сетевые сервисы для экспресс-анализа и интерпретации данных | ||
| Сетевые сервисы визуализации | | Сетевые сервисы визуализации | ||
| Использовать экспресс-методы | | Использовать экспресс-методы | ||
| | | [[RAWGraphs]], [[CODAP]], [[graphviz]] - примеры использования | ||
|- | |- | ||
| Обработать и очистить данные | | Обработать и очистить данные | ||
| Строка 147: | Строка 305: | ||
| Статистический анализ и интерпретация данных | | Статистический анализ и интерпретация данных | ||
| Операции над собственным датасетом | | Операции над собственным датасетом | ||
| Готовые датасеты | | Готовые датасеты [[:Category:Dataset]] | ||
|- | |- | ||
| Подготовка выполняемой публикации | | Подготовка выполняемой публикации | ||
| Экспорт результатов | | Экспорт результатов | ||
| Операции над собственным | | Операции над собственным [[датасет]]ом | ||
| [[Выполняемая публикация]] | | [[Выполняемая публикация]] | ||
|} | |} | ||
Текущая версия на 18:00, 21 мая 2024
| Планируемые результаты обучения (Знать, Уметь, Владеть) | В результате освоения дисциплины слушатель должен:
|
|---|---|
| Содержание разделов курса | Разделы:
|
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | BehaviorSpace, NetLogo, Scratch, Snap!, Сообщество Scratch, CODAP, RStudio, RAWGraphs |
| Книги, на которых основывается учебный курс |
Составляющие курса
Составляющие поля совместной деятельности
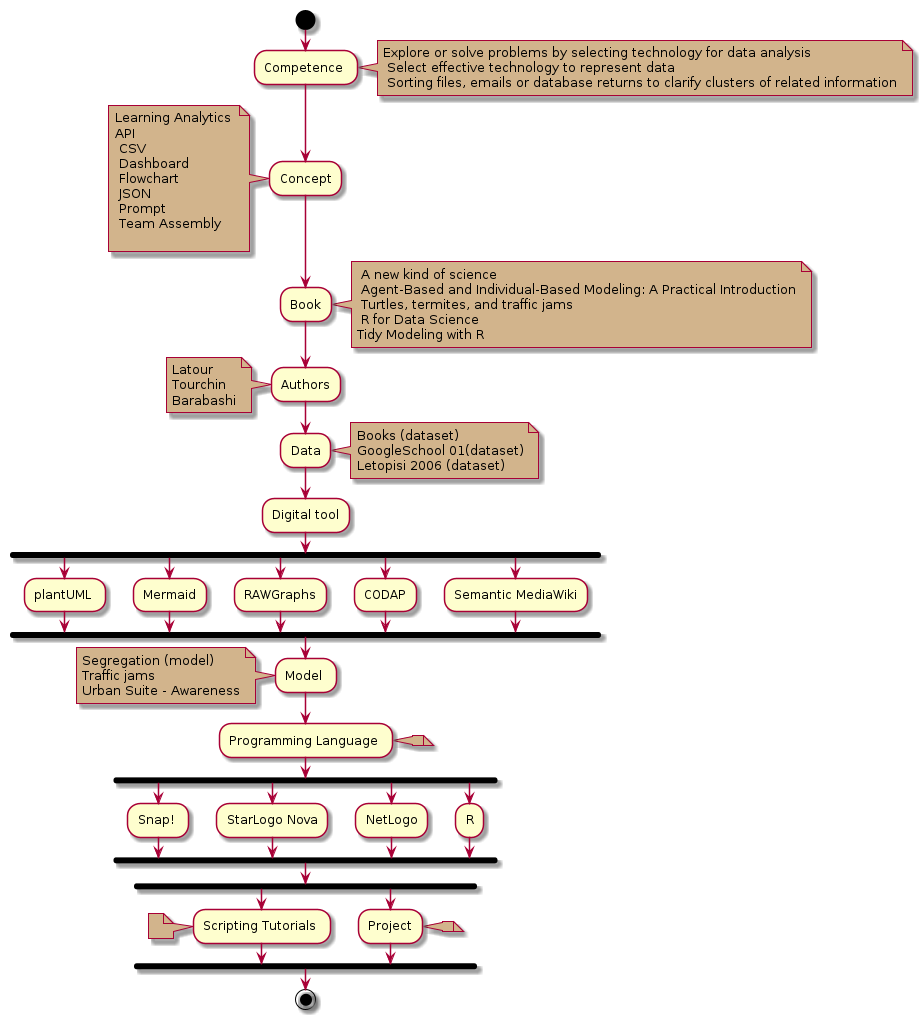
UML диаграмма - последовательность учебного курса
С какими данными и что мы будем делать
Источники и типы данных, которые мы извлекаем или порождаем - информационные системы организаций, библиографические системы, сетевые опросы, игры, симуляции, сетевые сообщества
Собственные данные вики и их визуализация
| Страниц | Статей | Редактирований | Участников | Файлов |
|---|---|---|---|---|
| 4596 | 1293 | 27537 | 862 | 1011 |
Библиографические данные
Zotero + ACM https://m.youtube.com/watch?v=vNvRVTWYwlw
Внешние данные
Выращивание данных
Как вырастить данные в искусственном сообществе
Многое как данные на примере Snap!
Планирование операций над данными
Планирование действий над данными при помощи UML диаграмм
Сетевые сервисы визуализации
Использование быстрых сетевых сервисов анализа и интерпретации данных – RAWGraphs, CODAP, NetBlox. Выбор способов представления данных
Задание с RAWGraphs
- Патаракин Е. Д. Выращивание и Анализ Данных в Веб Красноярск - Сибирский федеральный университет, 2021.C. 238–242.
- https://elibrary.ru/item.asp?id=46644731
- https://www.slnova.org/patarakin/projects/694467/
Обработка, очистка
Обработка, очистка и манипуляции с данными
Мы берём исходный датасет - Cities (dataset)
| Название | Страна | Население |
|---|---|---|
| Voronezh | RU | 1047549 |
| Samara | RU | 1163399 |
| Kazan | RU | 1243500 |
| Rostov-na-Donu | RU | 1130305 |
| Nizhniy Novgorod | RU | 1259013 |
| Moscow | RU | 10381222 |
| Saint Petersburg | RU | 5351935 |
| Volgograd | RU | 1013533 |
| Omsk | RU | 1172070 |
| Yekaterinburg | RU | 1495066 |
| Ufa | RU | 1120547 |
| Chelyabinsk | RU | 1202371 |
| Novosibirsk | RU | 1612833 |
| Krasnoyarsk | RU | 1090811 |
Внутри множество городов - миллионников из разных стран. И у всех координаты в виде
Пример очистки и преобразования данных:
Статистический анализ и интерпретация данных
Основные операции статистического анализа - Анализ данных
Экспорт результатов
Подготовка результатов для публикаций, создание выполняемых публикаций и динамических визуализаций
Литература
Тексты на поле вычислительной дидактики
Дополнительная литература
- Патаракин Е.Д., Ярмахов Б.Б. Выращивание данных для школьных виртуальных лабораторий // Вестник Российского Университета Дружбы Народов. Серия: Информатизация Образования. 2021. Vol. 18, № 4. c. 347–359.
- Патаракин Е.Д., Вачкова С.Н. Сетевой анализ коллективных действий над цифровыми образовательными объектами // Вестник Московского Городского Педагогического Университета. Серия: Педагогика И Психология. 2019. № 4 (50). c. 101–112.
Видеоматериалы
Критерии оценки по дисциплине
| Образовательный результат | Тема | Задание | Пример |
|---|---|---|---|
| Знает особенности типов и источников данных | Примеры источников данных | Найти, оформить, вырастить данные для дальнейшего анализа | В категории статей о датасетах Category:Dataset |
| планировать процесс обработки, визуализации, анализа и интерпретации данных при помощи UML | Планирование операций над данными | Создать схему цикла работы с данными | Пример |
| Умеет использовать сетевые сервисы для экспресс-анализа и интерпретации данных | Сетевые сервисы визуализации | Использовать экспресс-методы | RAWGraphs, CODAP, graphviz - примеры использования |
| Обработать и очистить данные | Обработка, очистка | Подготовить и видоизменить данные | Примеры видоизменения данных в Snap!, R, Python |
| Операции статистического анализа | Статистический анализ и интерпретация данных | Операции над собственным датасетом | Готовые датасеты Category:Dataset |
| Подготовка выполняемой публикации | Экспорт результатов | Операции над собственным датасетом | Выполняемая публикация |