Демографические данные России за 5 лет
- Автор: Студент группы - RabotaNS
Введение
В современном мире данные становятся фундаментальным ресурсом для понимания социальных процессов. Демографические показатели — такие как численность населения и ожидаемая продолжительность жизни — представляют собой не просто сухие статистические цифры, а важнейшие индикаторы социального благополучия, качества жизни и устойчивости развития общества. Эти данные позволяют нам отслеживать долгосрочные тренды, выявлять проблемные зоны и оценивать эффективность социальной политики. Данный проект иллюстрирует возможности репрезентации демографических данных Российской Федерации посредством стандартных инструментов на цифровой платформе Digida.
Данные и методы
Источники данных
Для данного исследования мы используем данные из открытой базы Our World in Data (OWID) — одного из наиболее авторитетных и широко используемых источников глобальной статистики. OWID предоставляет свободный доступ к данным о населении, здравоохранении, экономике, окружающей среде и многих других аспектах человеческого развития. Данные проходят тщательную проверку, документируются и регулярно обновляются, что делает их надёжной основой для исследований.В работе используются два сsv файла с данными по населению и продолжительности жизни во всех странах мира. Конкретно для нашего анализа мы используем два набора данных:
- Население (Population): Данные о общей численности населения России за период 2020-2024 годов. Эти данные представляют собой исторические оценки, основанные на национальных переписях населения, регистрах и демографических моделях.
- Ожидаемая продолжительность жизни (Life Expectancy): Данные о средней ожидаемой продолжительности жизни при рождении для России за тот же период. Этот показатель отражает среднее количество лет, которое предположительно проживёт новорождённый при условии, что текущие уровни смертности останутся неизменными на протяжении его жизни.
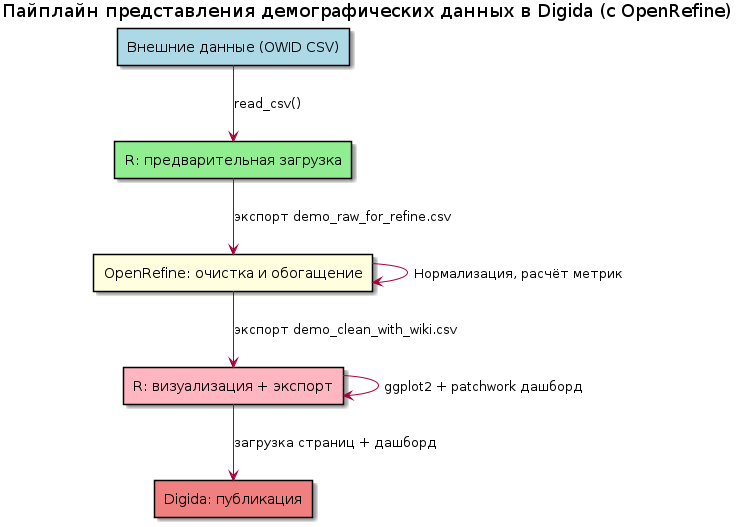
Очистка данных в OpenRefine
Исходные файлы OWID содержат данные по всем странам мира за длительный период времени. Для нашего исследования мы отбираем только записи, относящиеся к России и попадающие в интересующий нас временной диапазон (2020:2024). Это позволяет существенно сократить объём данных и ускорить последующую обработку.
Числовые данные могут содержать ошибки формата (например, текст вместо чисел, лишние пробелы, неправильные разделители десятичных дробей). Для обеспечения корректности последующих расчётов мы приводим все числовые колонки к единому формату.

После того как данные очищены и обогащены в OpenRefine, мы возвращаемся в R для создания визуализаций. Визуализация — это важно, ведь графики позволяют быстро уловить основные тренды и закономерности, которые могут быть неочевидны при просмотре таблиц с числами.
Код для получения данных
library(ggplot2)
library(patchwork)
library(dplyr)
library(readr)
library(scales)
options(encoding = "UTF-8")
# === НАСТРОЙКИ ===
data_path <- "C:/R/data/owid/" # ← ИЗМЕНИТЕ НА СВОЙ ПУТЬ!
country <- "Russia"
years <- 2020:2024
# === ФУНКЦИЯ: загрузка данных по России ===
load_russia <- function(filepath, value_col, new_name) {
if (!file.exists(filepath)) return(NULL)
tryCatch({
read_csv(filepath, show_col_types = FALSE) %>%
filter(Entity == country, Year %in% years) %>%
select(year = Year, !!new_name := all_of(value_col)) %>%
filter(!is.na(!!sym(new_name))) %>%
mutate(year = as.integer(year))
}, error = function(e) {
message(paste("⚠ Ошибка", filepath, ":", e$message))
NULL
})
}
# === ЗАГРУЗКА ДАННЫХ ===
cat("📊 Загрузка данных...\n")
# 1. Население (в млн)
df_pop <- load_russia(file.path(data_path, "population.csv"),
"Population (historical estimates)", "population")
if (!is.null(df_pop)) df_pop$population <- df_pop$population / 1e6
# 2. Продолжительность жизни
df_life <- load_russia(file.path(data_path, "life_expectancy.csv"),
"Life expectancy", "life_expectancy")
# Сборка датафрейма
df_final <- data.frame(year = years)
if (!is.null(df_pop)) df_final <- left_join(df_final, df_pop, by = "year")
if (!is.null(df_life)) df_final <- left_join(df_final, df_life, by = "year")
# === ДЕМО-ДАННЫЕ ЕСЛИ ФАЙЛЫ НЕ НАЙДЕНЫ ===
if (nrow(df_final) < 3 || sum(!is.na(df_final$population)) < 3) {
cat("⚠ Файлы не найдены. Используем демо-данные (на основе OWID).\n")
df_final <- data.frame(
year = 2020:2024,
population = c(146.7, 146.2, 145.5, 144.8, 144.0), # млн чел
life_expectancy = c(68.9, 70.1, 72.0, 72.6, 73.5) # лет
)
source_label <- "Demo (based on OWID)"
} else {
source_label <- "Our World in Data (локально)"
cat("✅ Данные загружены успешно.\n")
}
# === РАСЧЁТ ТЕМПОВ ИЗМЕНЕНИЯ ===
df_final <- df_final %>%
mutate(
pop_change = c(NA, diff(population) / population[-n()] * 100),
life_change = c(NA, diff(life_expectancy))
)
# === ВЫВОД СВОДКИ ===
cat(sprintf("\n📅 Период: %d - %d\n", min(years), max(years)))
if (!all(is.na(df_final$population))) {
cat(sprintf("👥 Население: %.1f → %.1f млн чел (%.2f%%)\n",
df_final$population[1], df_final$population[nrow(df_final)],
(tail(df_final$population, 1) - df_final$population[1]) / df_final$population[1] * 100))
}
if (!all(is.na(df_final$life_expectancy))) {
cat(sprintf("❤️ Продолжительность жизни: %.1f → %.1f лет (+%.1f)\n",
df_final$life_expectancy[1], df_final$life_expectancy[nrow(df_final)],
df_final$life_expectancy[nrow(df_final)] - df_final$life_expectancy[1]))
}
# === ГРАФИКИ ===
# 1. Динамика численности населения
p1 <- ggplot(df_final, aes(x = year, y = population)) +
geom_line(color = "#2E86AB", linewidth = 1.5) +
geom_point(size = 3, color = "#2E86AB") +
geom_text(aes(label = paste0(population, " млн")),
vjust = -1, size = 3.5, check_overlap = TRUE) +
scale_x_continuous(breaks = df_final$year) +
theme_minimal() +
labs(title = "Численность населения России",
subtitle = paste("Источник:", source_label),
x = "Год", y = "Млн человек") +
theme(plot.title = element_text(hjust = 0.5, face = "bold", size = 14))
# 2. Ожидаемая продолжительность жизни
p2 <- ggplot(df_final, aes(x = year, y = life_expectancy)) +
geom_col(fill = "#28A745", alpha = 0.85) +
geom_text(aes(label = paste0(life_expectancy, " лет")),
vjust = -0.5, size = 3.5) +
scale_x_continuous(breaks = df_final$year) +
scale_y_continuous(limits = c(60, max(df_final$life_expectancy, na.rm = TRUE) * 1.1)) +
theme_minimal() +
labs(title = "Продолжительность жизни",
x = "Год", y = "Лет") +
theme(plot.title = element_text(hjust = 0.5, face = "bold", size = 14))
# 3. Темп изменения населения (дополнительный мини-график)
p3 <- ggplot(df_final, aes(x = year, y = pop_change)) +
geom_col(fill = ifelse(df_final$pop_change >= 0, "#28A745", "#DC3545"),
alpha = 0.8, na.rm = TRUE) +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50") +
geom_text(aes(label = ifelse(is.na(pop_change), "",
paste0(round(pop_change, 2), "%"))),
vjust = ifelse(df_final$pop_change >= 0, -0.5, 1.5),
size = 3, na.rm = TRUE) +
scale_x_continuous(breaks = df_final$year) +
theme_minimal() +
labs(title = "Темп изменения населения",
x = "Год", y = "% к предыдущему году") +
theme(plot.title = element_text(hjust = 0.5, face = "bold", size = 12))
# === КОМПОНОВКА И СОХРАНЕНИЕ ===
final_plot <- (p1 / p2) + p3 +
plot_layout(heights = c(1, 1, 0.6)) &
theme(plot.margin = margin(10, 10, 10, 10), text = element_text(size = 10))
print(final_plot)
# Сохранение
output_file <- "russia_demographics_simple.png"
ggsave(output_file, final_plot, width = 14, height = 12, dpi = 300, bg = "white")
cat(sprintf("\n✅ Готово! Файл сохранён: %s\n", output_file))
Результаты
Дашборд демографических показателей

Расчеты, метрики
Темп изменения населения (годовой прирост/убыль) [math]\displaystyle{ p[t] = (P[t] - P[t-1]) / P[t-1] × 100% }[/math]
P[t] — численность населения в году t; P[t-1] — численность населения в предыдущем году Результат выражается в процентах (%)
Абсолютное изменение продолжительности жизни [math]\displaystyle{ ΔL[t] = L[t] - L[t-1] }[/math] L[t] — ожидаемая продолжительность жизни в году t (в годах) Результат выражается в годах (положительное значение = рост, отрицательное = снижение)
Общий темп роста за период [math]\displaystyle{ G = (P[end] - P[start]) / P[start] × 100% }[/math]
Показатели
- Население: 144.0 млн чел 144.0
- Продолжительность жизни: 73.5 лет 73.5
- Изменение населения: ↘ -0.55% -0.55
Выводы
Что показывают результаты?
- Устойчивое сокращение численности населения
- Тренд: Наблюдается стабильная нисходящая динамика.
- Цифры: Население уменьшилось с примерно 146,7 млн чел. в 2020 году до 144 млн чел. в 2024 году.
- Итог: За 4 года потеря составила около 2,7 млн человек.
- Рост продолжительности жизни
- Тренд: Несмотря на общее сокращение населения, показатель продолжительности жизни демонстрирует уверенный рост.
- Цифры: Показатель увеличился с 68,9 лет (2020 г.) до 73,5 лет (2024 г.).
- Итог: Прирост составил +4,6 года за период. Это указывает на улучшение условий жизни или здравоохранения, что позволяет людям жить дольше.
- Отрицательные темпы прироста
- Тренд: График «Темп изменения населения» показывает исключительно отрицательные значения (красные столбцы).
- Динамика: В 2021 году спад составил -0,34%.В 2022 и 2023 годах темп снижения ускорился до -0,48%. В 2024 году тенденция к снижению сохраняется (столбец сопоставим с предыдущими годами).
- Общий демографический парадокс
- Графики демонстрируют классическую ситуацию для развитых стран или стран в кризисе: «сжатие» населения при повышении его долголетия.
- Сокращение населения в данном случае не связано с ростом смертности (так как продолжительность жизни растет).
- Вероятные причины убыли (исходя из данных): низкая рождаемость или миграционный отток.
Приложения
- Our World in Data - https://ourworldindata.org
- API документация:
Население - https://ourworldindata.org/grapher/population.csv?v=1&csvType=full&useColumnShortNames=true
Продолжительность жизни - https://ourworldindata.org/grapher/life-expectancy.csv?v=1&csvType=full&useColumnShortNames=true
Редактор страницы
library(httr)
library(jsonlite)
url <- "https://digida.mgpu.ru/api.php"
response <- GET(url, query = list(
action = "query",
prop = "revisions",
titles = "Демографические данные России за 5 лет",
rvprop = "user|timestamp",
rvlimit = 100,
format = "json"
))
data <- content(response, as = "text", encoding = "UTF-8")
json_data <- fromJSON(data, flatten = TRUE)
pages <- json_data$query$pages
page <- pages[[1]]
revisions <- page$revisions
users <- revisions$user
head(users, 10)


