Анализ данных: различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| Строка 36: | Строка 36: | ||
Выделение необходимый данных, фильтрация, объединение. | Выделение необходимый данных, фильтрация, объединение. | ||
Например, выделить | Например, выделить первый столбец с данными об авторах | ||
[[Файл:WoS_collection_script_pic.png]] | [[Файл:WoS_collection_script_pic.png]] | ||
Версия 20:16, 2 февраля 2023
| Описание | После того, как мы собрали или вырастили данные, наступает этап их анализа. В прикладной науке о данных выделяется определённая последовательность действий, которые совершаются над данными для их лучшего понимания и объяснения. |
|---|---|
| Область знаний | NetSci, Археология, Информатика, Математика, История, Медицина |
| Область использования (ISTE) | Digital Citizen, Computational Thinker, Global Collaborator |
| Возрастная категория | 10
|
| Поясняющее видео | |
| Близкие рецепту понятия | Данные, Датасет, csv |
| Среды и средства для приготовления рецепта: | R, RStudio, Python, Snap! |
Последовательность операций над данными
В книге R for Data Science приводится следующая последовательность операций над данными:
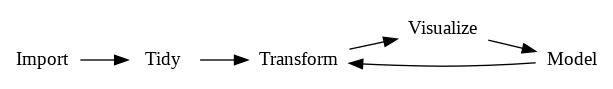
Import
- Датасет должен быть загружен в среду (файл с компьютера или данные из удалённого источника)
- Для Snap! просто вбросить CSV файл с данными в среду и возникнет переменная (список списков) с именем файла
- Для R read.csv() read.csv2() или загрузка через меню Import.Dataset
- g1 <- read_rds("pregraph_06_19.rds")
Tidy
Общее правило - в строке только одна переменная, в столбцах только одно измеряемое значение.
Transform
Выделение необходимый данных, фильтрация, объединение. Например, выделить первый столбец с данными об авторах

Видео пояснения