Обсуждение участника:Алёна Зайцева
Процесс заказа в интернет-магазине в Mermaid
Эта схема последовательности описывает взаимодействие клиента, системы магазина и склада:
Выбор товара: клиент выбирает товар и добавляет его в корзину.
Подтверждение добавления: система магазина подтверждает добавление и показывает сумму.
Оформление заказа: клиент переходит к оформлению заказа.
Проверка наличия: система отправляет запрос на склад для проверки наличия товара.
Подтверждение наличия: склад подтверждает, что товар есть в наличии.
Подтверждение заказа: система уведомляет клиента, что заказ подтверждён и ожидает доставку.
Получение заказа: клиент уведомляет систему о получении товара.
Завершение заказа: система благодарит клиента за заказ.
Схема иллюстрирует ключевые этапы процесса онлайн-покупки — от выбора товара до подтверждения получения.
Процесс заказа в интернет-магазине в Graphviz
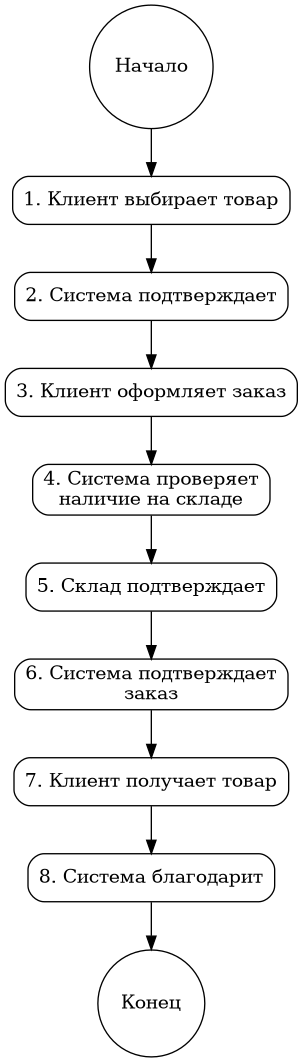
Это линейная блок-схема процесса онлайн-заказа в интернет-магазине, состоящая из 8 последовательных шагов:
1. Выбор товара клиентом
2. Подтверждение системой магазина
3. Оформление заказа клиентом
4. Проверка наличия системы со складом
5. Подтверждение наличия складом
6. Подтверждение заказа системой клиенту
7. Получение товара клиентом
8. Завершение с благодарностью от системы
R-script анализ Зайцева Алёна
Описание
Датасет был взят с Категория:Dataset
Датасет Food содержит данные по различным видам продуктов питания, включая количество различных витаминов и минералов, содержащихся в продуктах, а также процентное содержание макроэлементов.: https://corgis-edu.github.io/corgis/datasets/csv/food/food.csv
Код
# Подключаем библиотеки
library(tidyverse)
library(tidytext)
library(ggplot2)
library(wordcloud)
library(patchwork)
# Читаем данные и сразу чистим имена колонок
data <- read_csv("https://corgis-edu.github.io/corgis/datasets/csv/food/food.csv", show_col_types = FALSE)
glimpse(data)
# 1. Общее количество записей (строк) в датасете
total_records <- nrow(data)
print(paste("Всего продуктов в датасете:", total_records))
# 2. Общее количество слов в колонке Description (описание продукта)
total_words_desc <- sum(str_count(data$Description, "\\S+"))
print(paste("Всего слов в описаниях продуктов:", total_words_desc))
# 3. Топ-10 самых частых слов в описаниях продуктов
top10_words <- data %>%
separate_rows(Description, sep = " ") %>% # разбиваем описания на отдельные слова
count(word = Description, sort = TRUE) %>% # считаем частоту каждого слова
head(10) # берём топ-10
print("10 самых частых слов в описаниях продуктов:")
print(top10_words)
# 4. Топ-10 категорий продуктов по числу записей
top_categories <- data %>%
count(Category, sort = TRUE) %>%
head(10)
print("Топ-10 категорий продуктов:")
print(top_categories)
# 5. Топ-10 биграмм (пар слов) в описаниях продуктов
# Используем tidytext для создания биграмм
bigrams <- data %>%
unnest_tokens(bigram, Description, token = "ngrams", n = 2) %>%
count(bigram, sort = TRUE) %>%
separate(bigram, into = c("word1", "word2"), sep = " ", remove = FALSE) %>%
filter(!is.na(word1), !is.na(word2)) %>%
head(10)
print("Топ-10 биграмм в описаниях продуктов:")
print(bigrams)
# Визуализация топ-10 биграмм (горизонтальная столбчатая диаграмма)
bigrams %>%
mutate(bigram = reorder(bigram, n)) %>%
ggplot(aes(x = n, y = bigram)) +
geom_col(fill = "steelblue") +
labs(title = "Топ-10 самых частых биграмм в описаниях продуктов",
x = "Частота", y = "Биграмма") +
theme_minimal()
Пример выполнения кода
.png)

Результаты
Топ-10 слов
| Слово | Частота |
|---|---|
| with | 2235 |
| or | 1534 |
| and | 1216 |
| fat | 1033 |
| as | 585 |
| added | 580 |
| to | 577 |
| NS | 561 |
| made | 556 |
| no | 512 |
Топ-10 биграмм
| Биграмма | 1 слово | 2 слово | Количество |
|---|---|---|---|
| as to | as | to | 560 |
| ns as | ns | as | 560 |
| made with | made | with | 486 |
| added fat | added | fat | 284 |
| no added | no | added | 284 |
| fat added | fat | added | 250 |
| dark green | dark | green | 248 |
| to fat | to | fat | 227 |
| baby food | baby | food | 225 |
| and vegetables | and | vegetables | 222 |
Визуализация

Выводы
Корпус состоит из 1028 описаний продуктов, содержащих 12345 слов. TTR равен 0.1876 — это низкий показатель, что говорит о высокой повторяемости слов и узкой тематической направленности корпуса.
Среди частотных слов лидируют термины, связанные с молочной продукцией: «milk» (345), «low» (298), «fat» (276), «nonfat» (189), «cheese» (167). Это указывает на доминирование молочных и молокосодержащих продуктов в датасете. Топ-10 категорий подтверждают это: «Cheese», «Yogurt», «Milk», «Infant formula», «Ice cream» и др.
Наиболее частотные биграммы — «low fat», «fat free», «ready to», «skim milk», «whole milk» — акцентируют внимание на жирности и консистенции продуктов. Таким образом, корпус представляет собой специализированный словарь пищевых ингредиентов с сильным уклоном в молочную группу и её диетические вариации.

