Методы анализа больших данных (Syllabus) 2025/Lesson ML
Материал из Поле цифровой дидактики
Урок по анализу данных с использованием методов машинного обучения
D1

D 2
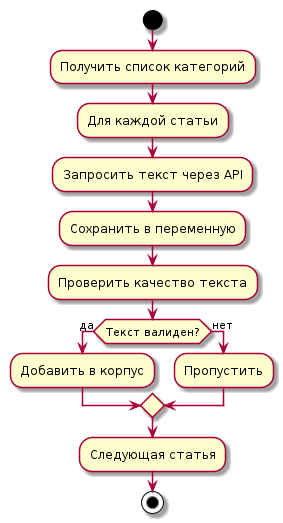
Диаграмма процесса очистки текста

Процесс получения данных
library(httr)
library(jsonlite)
library(xml2)
library(tidyverse)
library(quanteda)
# Установка дополнительных пакетов
library(stopwords)
library(stringr)
###########
get_wikipedia_category_members <- function(category_name, language = "ru") {
# Базовый URL API
base_url <- paste0("https://", language, ".wikipedia.org/w/api.php")
all_members <- data.frame()
continue_token <- NULL
repeat {
# Формируем параметры запроса
params <- list(
action = "query",
list = "categorymembers",
cmtitle = paste0("Category:", category_name),
cmlimit = 500, # Максимум результатов за раз
format = "json",
cmtype = "page", # Только статьи, не категории
cmcontinue = continue_token
)
# Выполняем запрос
response <- GET(base_url, query = params)
# Проверяем статус ответа
if (status_code(response) != 200) {
warning("Ошибка при запросе к API: статус ", status_code(response))
break
}
# Парсим JSON
data <- fromJSON(content(response, as = "text", encoding = "UTF-8"))
# Извлекаем члены категории
if (!is.null(data$query$categorymembers)) {
members <- data$query$categorymembers %>%
as_tibble() %>%
select(pageid, title)
all_members <- bind_rows(all_members, members)
}
# Проверяем, есть ли продолжение запроса
if (is.null(data$`query-continue`$categorymembers$cmcontinue)) {
break
}
continue_token <- data$`query-continue`$categorymembers$cmcontinue
}
return(all_members)
}
iot_articles <- get_wikipedia_category_members("Интернет вещей")
cat("Найдено статей:", nrow(iot_articles), "\n")
head(iot_articles)

