Методы анализа больших данных (Syllabus) 2025/Lesson ML: различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) |
Patarakin (обсуждение | вклад) |
||
| Строка 125: | Строка 125: | ||
head(iot_articles) | head(iot_articles) | ||
###################### | |||
get_wikipedia_text <- function(article_title, language = "ru") { | |||
base_url <- paste0("https://", language, ".wikipedia.org/w/api.php") | |||
params <- list( | |||
action = "query", | |||
titles = article_title, | |||
prop = "extracts", | |||
explaintext = TRUE, # Получаем чистый текст без Wiki-разметки | |||
format = "json" | |||
) | |||
response <- GET(base_url, query = params) | |||
if (status_code(response) != 200) { | |||
return(NA) | |||
} | |||
data <- fromJSON(content(response, as = "text", encoding = "UTF-8")) | |||
# Извлекаем текст из ответа | |||
pages <- data$query$pages | |||
page_id <- names(pages)[1] | |||
if (!is.null(pages[[page_id]]$extract)) { | |||
return(pages[[page_id]]$extract) | |||
} else { | |||
return(NA) | |||
} | |||
} | |||
# Сбираем тексты для всех найденных статей | |||
# Добавляем задержку между запросами, чтобы не перегружать сервер | |||
collected_texts <- tibble( | |||
title = character(), | |||
text = character() | |||
) | |||
for (i in seq_len(min(nrow(iot_articles), 50))) { # Возьмём первые 50 статей для примера | |||
if (i %% 10 == 0) { | |||
cat("Обработано статей:", i, "\n") | |||
} | |||
article_title <- iot_articles$title[i] | |||
article_text <- get_wikipedia_text(article_title) | |||
if (!is.na(article_text)) { | |||
collected_texts <- add_row(collected_texts, | |||
title = article_title, | |||
text = article_text) | |||
} | |||
# Задержка между запросами (500 мс) | |||
Sys.sleep(0.5) | |||
} | |||
cat("Успешно получено текстов:", nrow(collected_texts), "\n") | |||
########################### | |||
# Функция для предварительной очистки текста | |||
preprocess_text <- function(text) { | |||
# Приведение к нижнему регистру | |||
text <- tolower(text) | |||
# Удаление URL | |||
text <- str_remove_all(text, "https?://[^\\s]+") | |||
# Удаление специальных символов, но сохраняем буквы и пробелы | |||
text <- str_remove_all(text, "[^а-яА-Яa-zA-Z\\s]") | |||
# Удаление множественных пробелов | |||
text <- str_squish(text) | |||
return(text) | |||
} | |||
# Применяем предварительную очистку | |||
cleaned_texts <- collected_texts %>% | |||
mutate( | |||
cleaned_text = map_chr(text, preprocess_text) | |||
) | |||
head(cleaned_texts$cleaned_text, 1) | |||
### Работа с пакетом quanteda | |||
# Создание корпуса | |||
corpus_texts <- corpus(cleaned_texts, | |||
docid_field = "title", | |||
text_field = "cleaned_text") | |||
cat("Корпус создан. Документов:", ndoc(corpus_texts), "\n") | |||
cat("Токенов:", ntoken(corpus_texts), "\n") | |||
# Токенизация текста | |||
tokens_data <- tokens(corpus_texts, | |||
remove_punct = TRUE, | |||
remove_numbers = TRUE, | |||
remove_separators = TRUE) | |||
# Приведение к нижнему регистру | |||
tokens_data <- tokens_tolower(tokens_data) | |||
# Получение русских стоп-слов | |||
russian_stopwords <- stopwords("russian") | |||
# Удаление стоп-слов | |||
tokens_clean <- tokens_select(tokens_data, | |||
pattern = russian_stopwords, | |||
selection = "remove", | |||
min_nchar = 3) # Удаляем слова короче 3 символов | |||
# Стемминг (приведение к корню слова) | |||
tokens_stemmed <- tokens_wordstem(tokens_clean, language = "russian") | |||
cat("Размер словаря после очистки:", ntype(tokens_stemmed), "\n") | |||
# Создание матрицы документ-термин | |||
dtm <- dfm(tokens_stemmed) | |||
cat("Размеры DTM: ", nrow(dtm), " документов, ", ncol(dtm), " термов\n", sep = "") | |||
# Просмотр структуры | |||
head(dtm) | |||
# Топ-10 самых частых слов | |||
topfeatures(dtm, 10) | |||
# Фильтрация редких слов | |||
# Оставляем слова, которые встречаются минимум в 2 документах | |||
# и имеют минимум 5 вхождений в корпусе | |||
dtm_trimmed <- dfm_trim(dtm, | |||
min_docfreq = 2, # мин. документы | |||
min_termfreq = 5) # мин. вхождения | |||
cat("Размеры отфильтрованной DTM: ", nrow(dtm_trimmed), " документов, ", | |||
ncol(dtm_trimmed), " термов\n", sep = "") | |||
# Вычисление TF-IDF (Term Frequency-Inverse Document Frequency) | |||
dtm_tfidf <- dfm_tfidf(dtm_trimmed) | |||
cat("TF-IDF матрица готова\n") | |||
</syntaxhighlight> | </syntaxhighlight> | ||
Версия от 12:30, 14 ноября 2025
Урок по анализу данных с использованием методов машинного обучения
D1

D 2
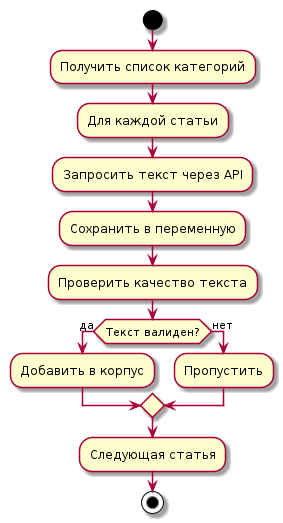
Диаграмма процесса очистки текста

Процесс получения данных
library(httr)
library(jsonlite)
library(xml2)
library(tidyverse)
library(quanteda)
# Установка дополнительных пакетов
library(stopwords)
library(stringr)
###########
get_wikipedia_category_members <- function(category_name, language = "ru") {
# Базовый URL API
base_url <- paste0("https://", language, ".wikipedia.org/w/api.php")
all_members <- data.frame()
continue_token <- NULL
repeat {
# Формируем параметры запроса
params <- list(
action = "query",
list = "categorymembers",
cmtitle = paste0("Category:", category_name),
cmlimit = 500, # Максимум результатов за раз
format = "json",
cmtype = "page", # Только статьи, не категории
cmcontinue = continue_token
)
# Выполняем запрос
response <- GET(base_url, query = params)
# Проверяем статус ответа
if (status_code(response) != 200) {
warning("Ошибка при запросе к API: статус ", status_code(response))
break
}
# Парсим JSON
data <- fromJSON(content(response, as = "text", encoding = "UTF-8"))
# Извлекаем члены категории
if (!is.null(data$query$categorymembers)) {
members <- data$query$categorymembers %>%
as_tibble() %>%
select(pageid, title)
all_members <- bind_rows(all_members, members)
}
# Проверяем, есть ли продолжение запроса
if (is.null(data$`query-continue`$categorymembers$cmcontinue)) {
break
}
continue_token <- data$`query-continue`$categorymembers$cmcontinue
}
return(all_members)
}
iot_articles <- get_wikipedia_category_members("Интернет вещей")
cat("Найдено статей:", nrow(iot_articles), "\n")
head(iot_articles)
######################
get_wikipedia_text <- function(article_title, language = "ru") {
base_url <- paste0("https://", language, ".wikipedia.org/w/api.php")
params <- list(
action = "query",
titles = article_title,
prop = "extracts",
explaintext = TRUE, # Получаем чистый текст без Wiki-разметки
format = "json"
)
response <- GET(base_url, query = params)
if (status_code(response) != 200) {
return(NA)
}
data <- fromJSON(content(response, as = "text", encoding = "UTF-8"))
# Извлекаем текст из ответа
pages <- data$query$pages
page_id <- names(pages)[1]
if (!is.null(pages[[page_id]]$extract)) {
return(pages[[page_id]]$extract)
} else {
return(NA)
}
}
# Сбираем тексты для всех найденных статей
# Добавляем задержку между запросами, чтобы не перегружать сервер
collected_texts <- tibble(
title = character(),
text = character()
)
for (i in seq_len(min(nrow(iot_articles), 50))) { # Возьмём первые 50 статей для примера
if (i %% 10 == 0) {
cat("Обработано статей:", i, "\n")
}
article_title <- iot_articles$title[i]
article_text <- get_wikipedia_text(article_title)
if (!is.na(article_text)) {
collected_texts <- add_row(collected_texts,
title = article_title,
text = article_text)
}
# Задержка между запросами (500 мс)
Sys.sleep(0.5)
}
cat("Успешно получено текстов:", nrow(collected_texts), "\n")
###########################
# Функция для предварительной очистки текста
preprocess_text <- function(text) {
# Приведение к нижнему регистру
text <- tolower(text)
# Удаление URL
text <- str_remove_all(text, "https?://[^\\s]+")
# Удаление специальных символов, но сохраняем буквы и пробелы
text <- str_remove_all(text, "[^а-яА-Яa-zA-Z\\s]")
# Удаление множественных пробелов
text <- str_squish(text)
return(text)
}
# Применяем предварительную очистку
cleaned_texts <- collected_texts %>%
mutate(
cleaned_text = map_chr(text, preprocess_text)
)
head(cleaned_texts$cleaned_text, 1)
### Работа с пакетом quanteda
# Создание корпуса
corpus_texts <- corpus(cleaned_texts,
docid_field = "title",
text_field = "cleaned_text")
cat("Корпус создан. Документов:", ndoc(corpus_texts), "\n")
cat("Токенов:", ntoken(corpus_texts), "\n")
# Токенизация текста
tokens_data <- tokens(corpus_texts,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_separators = TRUE)
# Приведение к нижнему регистру
tokens_data <- tokens_tolower(tokens_data)
# Получение русских стоп-слов
russian_stopwords <- stopwords("russian")
# Удаление стоп-слов
tokens_clean <- tokens_select(tokens_data,
pattern = russian_stopwords,
selection = "remove",
min_nchar = 3) # Удаляем слова короче 3 символов
# Стемминг (приведение к корню слова)
tokens_stemmed <- tokens_wordstem(tokens_clean, language = "russian")
cat("Размер словаря после очистки:", ntype(tokens_stemmed), "\n")
# Создание матрицы документ-термин
dtm <- dfm(tokens_stemmed)
cat("Размеры DTM: ", nrow(dtm), " документов, ", ncol(dtm), " термов\n", sep = "")
# Просмотр структуры
head(dtm)
# Топ-10 самых частых слов
topfeatures(dtm, 10)
# Фильтрация редких слов
# Оставляем слова, которые встречаются минимум в 2 документах
# и имеют минимум 5 вхождений в корпусе
dtm_trimmed <- dfm_trim(dtm,
min_docfreq = 2, # мин. документы
min_termfreq = 5) # мин. вхождения
cat("Размеры отфильтрованной DTM: ", nrow(dtm_trimmed), " документов, ",
ncol(dtm_trimmed), " термов\n", sep = "")
# Вычисление TF-IDF (Term Frequency-Inverse Document Frequency)
dtm_tfidf <- dfm_tfidf(dtm_trimmed)
cat("TF-IDF матрица готова\n")

