Язык программирования R (syllabus) 2026: различия между версиями
Материал из Поле цифровой дидактики
Patarakin (обсуждение | вклад) Новая страница: «{{Curriculum |Environment=R |Book=R for Data Science }} == Последовательность курса == <uml> @startuml skinparam NoteBackgroundColor tan skinparam backgroundColor white skinparam activity { BackgroundColor lightblue BorderColor navy } start :Факультатив "R для Digida Big Data"; note right 4 занятия, 1.5–2 часа каждое Связь: результаты → курс "Методы...» |
Patarakin (обсуждение | вклад) Нет описания правки |
||
| (не показаны 2 промежуточные версии этого же участника) | |||
| Строка 1: | Строка 1: | ||
{{Curriculum | {{Curriculum | ||
|Learning_outcomes=Знать | |||
* основные особенности языка R и его роль в анализе данных ; | |||
* принципы tidy data: строка = наблюдение, столбец = переменная; | |||
* базовые возможности пакетов dplyr, httr/jsonlite, ggplot2 для обработки, получения и визуализации данных; | |||
* общую схему работы с данными курса: Digida/NetLogo → CSV/API → R → визуализация → публикация на Digida. | |||
; Уметь | |||
* настраивать рабочую среду R/RStudio и загружать данные из CSV‑файлов; | |||
* выполнять базовую обработку данных в R: фильтрацию, выбор столбцов, группировку, агрегирование с помощью `%>%` и dplyr; | |||
* получать данные по HTTP и из MediaWiki API (Digida) и преобразовывать их в таблицы; | |||
* строить простые графики в ggplot2 (столбчатые, линейные, точечные) и сохранять результаты; | |||
* документировать полный рецепт обработки данных на странице Digida (код, данные, результаты, вывод). | |||
; Владеть | |||
* базовыми приёмами потоковой обработки данных в R с использованием pipe‑нотации; | |||
* навыками интеграции R‑скриптов с инфраструктурой Digida | |||
|Description=; Введение в язык R и настройка рабочей среды | |||
* обзор языка R и RStudio; | |||
* установка и выбор рабочей директории; | |||
* загрузка данных из CSV (логи Digida, результаты NetLogo); | |||
* базовые операции: просмотр данных, размер, типы столбцов. | |||
; Элементы языка программирования R и tidydata | |||
* векторы, data.frame, основы индексирования; | |||
* пакет dplyr: `filter`, `select`, `mutate`, `group_by`, `summarise`; | |||
* оператор pipe `%>%` и построение цепочек преобразований; | |||
* tidydata и приведение исходных логов/экспериментов к опрятному виду. | |||
; Получение данных из файлов, по HTTP и через MediaWiki API | |||
* повторение `read.csv` для локальных файлов (Digida/NetLogo CSV); | |||
* пакет httr: выполнение GET‑запросов; | |||
* пакет jsonlite: преобразование JSON в таблицы; | |||
* примеры запросов к MediaWiki API Digida (recentchanges и др.); | |||
* объединение данных из нескольких источников (merge/join). | |||
; Визуализация данных и R‑рецепты для Digida | |||
* базовые графики в ggplot2: `geom_col`, `geom_line`, `geom_point`; | |||
* настройка подписей, осей, тем и сохранение графиков (ggsave); | |||
* структура R‑рецепта: описание задачи, данные, код, таблицы, графики, выводы; | |||
* создание страницы в категории RRecipe на Digida с полным рецептом извлечения и анализа данных. | |||
|Environment=R | |Environment=R | ||
|Book=R for Data Science | |Book=R for Data Science | ||
}} | }} | ||
== Последовательность курса == | == Последовательность курса == | ||
| Строка 17: | Строка 55: | ||
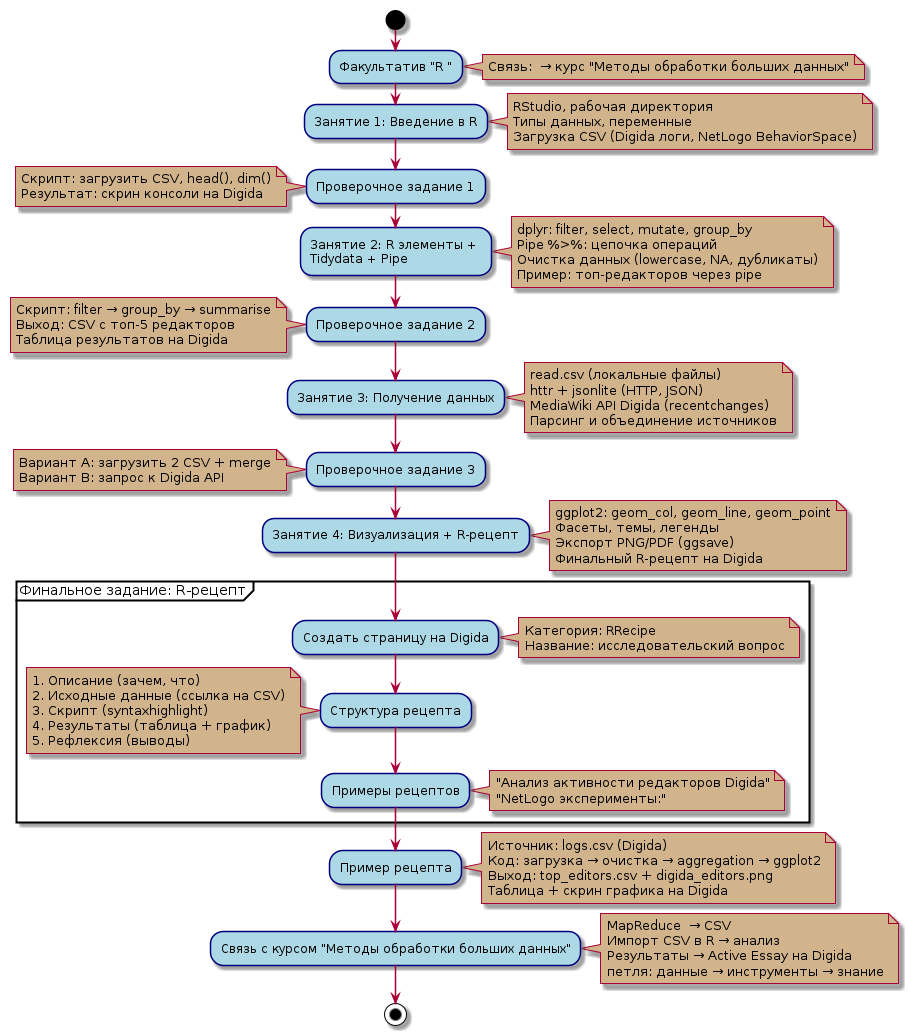
start | start | ||
:Факультатив "R | :Факультатив "R "; | ||
note right | note right | ||
Связь: → курс "Методы обработки больших данных" | |||
Связь: | |||
end note | end note | ||
| Строка 34: | Строка 71: | ||
Скрипт: загрузить CSV, head(), dim() | Скрипт: загрузить CSV, head(), dim() | ||
Результат: скрин консоли на Digida | Результат: скрин консоли на Digida | ||
end note | end note | ||
:Занятие 2: R элементы + | :Занятие 2: R элементы + \nTidydata + Pipe; | ||
note right | note right | ||
dplyr: filter, select, mutate, group_by | dplyr: filter, select, mutate, group_by | ||
| Строка 50: | Строка 86: | ||
Выход: CSV с топ-5 редакторов | Выход: CSV с топ-5 редакторов | ||
Таблица результатов на Digida | Таблица результатов на Digida | ||
end note | end note | ||
| Строка 65: | Строка 100: | ||
Вариант A: загрузить 2 CSV + merge | Вариант A: загрузить 2 CSV + merge | ||
Вариант B: запрос к Digida API | Вариант B: запрос к Digida API | ||
end note | end note | ||
| Строка 82: | Строка 115: | ||
Категория: RRecipe | Категория: RRecipe | ||
Название: исследовательский вопрос | Название: исследовательский вопрос | ||
end note | end note | ||
| Строка 97: | Строка 129: | ||
note right | note right | ||
"Анализ активности редакторов Digida" | "Анализ активности редакторов Digida" | ||
"NetLogo эксперименты: | "NetLogo эксперименты:" | ||
end note | end note | ||
} | } | ||
| Строка 110: | Строка 141: | ||
end note | end note | ||
:Связь с курсом "Методы обработки больших данных"; | :Связь с курсом "Методы обработки больших данных"; | ||
note right | note right | ||
MapReduce | MapReduce → CSV | ||
Импорт CSV в R → анализ | Импорт CSV в R → анализ | ||
Результаты → Active Essay на Digida | Результаты → Active Essay на Digida | ||
петля: данные → инструменты → знание | |||
end note | end note | ||
Текущая версия от 21:31, 15 февраля 2026
| Планируемые результаты обучения (Знать, Уметь, Владеть) | Знать
|
|---|---|
| Содержание разделов курса | ; Введение в язык R и настройка рабочей среды
|
| Видео запись | |
| Среды и средства, которые поддерживают учебный курс | R |
| Книги, на которых основывается учебный курс | R for Data Science |
Последовательность курса